pppenger.github.io
目录
Java 与 C++ 的区别OOP面向对象编程三大特征:抽象封装继承多态引用多态方法多态方法重载:方法覆盖:六大原则:一、单一职责原则:二、开闭原则:三、里氏替换原则:四、依赖倒置原则:五、接口隔离原则:六、迪米特原则:java访问修饰符java变量变量定义:命名规范:变量类型:数据类型基本数据类型Switch支持的数据类型方法传递参数原则:常量数组数组是类吗创建数组数组扩容二维数组Arrays类length,length(),size()的区别位运算符逻辑运算符运算符优先级泛型java开发——为什么要使用泛型?用Object不行吗?staticJava 中的 static 使用之静态变量Java 中的 static 使用之静态方法Java 中的 static 使用之静态初始化块java在创建对象时候 成员的执行顺序final关键字final修饰类时final修饰方法时final修饰变量时final修饰变量时的赋值问题:关于final和static什么是 Java 中的内部类Java 中的成员内部类Java 中的静态内部类Java 中的方法内部类引用类型转换接口interface匿名内部类Java API 简介java.lang 包一、String0.java中String new和直接赋值的区别1.Java 中 String 类的常用方法 Ⅰ2.Java 中的 String 类常用方法 Ⅱ3.java中字符串和字符数组的转换?4.StringBuilder 和StringBufferStringBufferStringBuilder Java 中基本类型和字符串之间的转换valueOf与parseInt方法二、包装类1.Integer 类2.Character 类3.Boolean 类三、Math四、类 Class五、反射六、注解Annotation注解的用处:注解的原理:元注解:常见标准的Annotation:七、Object类toString()方法equals和==的区别java日期和随机数一、java.util 和 java.time 包介绍二、Date 类和Calendar 类三、java.time 包四、Random 类Java 集合框架一、Collection 接口二、Map接口三、List 接口与 ArrayList 类四、Set 接口和 HashSet 类五、Quere接口五、HashSet和HashMap的区别六、HashMap 类七、HashTable八、ConcurrentHashMap的实现——JDK7版本九、JDK8中的ConcurrentHashMap十、ConcurrentHashMap总结十一、结合Util工具包Java io一、字节流1、基类:InputStream 和 OutputStream2、文件流3、缓冲流(速度快)4、 数据流5、标准流、内存读写流、顺序输入流二、字符流1、基类:Reader 和 Writer2、InputStreamReader 和 OutputStreamWriter3、缓存流4、其它字符流类三、File文件操作四、RandomAccessFile类五、Serializable(序列化)Java并发性和多线程进程并行和并发线程和进程的区别?线程线程状态为什么没有Running(正在运行状态)?线程的使用run()和start()方法区别:与线程生命周期相关的方法一、sleepobj.wait()wait() 和 sleep() 的区别二、yield方法三、join方法四、interrupt方法InterruptedException五、线程优先级设置线程池synchronized1. 同步一个代码块2. 同步一个方法3. 同步一个类4. 同步一个静态方法Lock显式锁synchronized锁和Lock锁使用哪个线程之间的协作wait() notify() notifyAll()await() signal() signalAll()J.U.C - AQS信号量CountDownLatchCyclicBarrierSemaphoreThreadLocal原子性可见性volatile线程安全不可变非阻塞同步无同步方案
Java 与 C++ 的区别
- Java 是纯粹的面向对象语言,所有的对象都继承自 java.lang.Object,C++ 为了兼容 C 即支持面向对象也支持面向过程。
- Java 通过虚拟机从而实现跨平台特性,但是 C++ 依赖于特定的平台。
- Java 没有指针,它的引用可以理解为安全指针,而 C++ 具有和 C 一样的指针。
- Java 支持自动垃圾回收,而 C++ 需要手动回收。
- Java 不支持多重继承,只能通过实现多个接口来达到相同目的,而 C++ 支持多重继承。
- Java 不支持操作符重载,虽然可以对两个 String 对象执行加法运算,但是这是语言内置支持的操作,不属于操作符重载,而 C++ 可以。
- Java 的 goto 是保留字,但是不可用,C++ 可以使用 goto。
- Java 不支持条件编译,C++ 通过 #ifdef #ifndef 等预处理命令从而实现条件编译。
OOP面向对象编程
把计算机中的东西比喻成现实生活中的一样事物,一个对象。那现实生活中的对象都会有属性跟行为,这就对应着计算机中的属性和方法(函数)。
OOP就是我们不是一个流程走到底,而是直接操作多个对象来实现想做的任务。
三大特征:
抽象
我们在定义一个类的时候,实际上就是把一类事物的公有的属性和行为提取出来,形成一个物理模型,这种研究问题的方法称为抽象。
封装
1.概念:将类的信息隐藏在类内部,不允许外部程序直接访问,而是通过该类提供的方法来实现对隐藏信息的操作和访问
2.好处:
a.只能通过规定的方法访问数据
b.隐藏类的实例细节,方便修改和实现
继承
继承可以解决代码复用问题,让我们编程更加靠近人类的思维,当多个类存在相同的属性(变量)和方法时,可以从这些类中抽象出父类(比如刚才的Student),在父类中定义这些相同的属性和方法,所有的子类不需要重新定义这些属性和方法,只需要通过extend语句来声明继承 父类:
class 子类 extends 父类 这样,子类就会自动拥有父类定义的属性和方法。
继承注意事项:
子类最多继承一个父类 java多有类都是Object类的子类
多态
所谓多态,就是指一个引用(类型)在不同情况下的多种状态,你也可以这样理解:多态是指通过指向父类的指针,来调用在不同子类中实现的方法
引用多态
父类的引用可以指向本类的对象 父类的引用可以指向子类的对象
方法多态
创建本类对象时,调用的方法为本类方法 创建子类对象时,调用的方法为之类重写的方法或者继承的方法
方法重载:
简单地说:方法重载就是类的同一种功能的多种实现方式,到底采用哪种方式,取决于调用者给出的参数。
方法重载-注意事项
1.方法名相同
2.方法的参数类型、个数、顺序至少有一项不同
3.仅仅是返回类型不一样,是不能构成重载的
4.方法修饰符可以不同
5.如果只是控制访问符不同,不能构成重载
方法覆盖:
将父类的方法进行重新写。方法的覆盖就是子类有一个方法,和父类的某个方法的名称、返回类型、参数一样,那么我们就说子类的这个方法覆盖了父类的那个方法,比如上个案例的Cat类中的cry方法就覆盖了Animal类的cry方法。
方法覆盖的注意事项:
(1)子类的方法的返回类型,参数,方法名称,要和父类方法的返回类型,参数,方法名称完全一样,否则编译出错。
(2)子类方法不能缩小父类方法的访问权限。(假设父类方法时public,但是你的子类方法改成了protected,这样就会出现报错)
六大原则:
一、单一职责原则:
单一职责原则的定义是就一个类而言,应该仅有一个引起他变化的原因。也就是说一个类应该只负责一件事情。
比如:我们在写一个简单画图板时,一般把画图板界面与画图板上的监听器分成两个类去完成。这样的好处比如我们只想改变画图板界面时,监听器类就可以直接调用,不必重新编写。可以降低类的复杂性,提高类的可读性和系统的维护性。
二、开闭原则:
开闭原则的定义是软件中的对象(类,模块,函数等)应该对于扩展是开放的,但是对于修改是关闭的。
比如对person父类中有很多方法,但想在增加study的方法时,不要直接在父类中修改,可以在student子类中扩展study方法。这样可以提高方法的复用性和系统的维护性。
三、里氏替换原则:
简单来说就是子类可以扩展父类功能,但是不能改变其原有的功能。可以有以下这些理解:
子类可以实现父类的抽象方法,但是不能覆盖父类的非抽象方法。 子类可以增加自己独有的方法。 当子类的方法重载父类的方法时候,方法的形参要比父类的方法的输入参数更加宽松。 当子类的方法实现父类的抽象方法时,方法的返回值要比父类更严格。
四、依赖倒置原则:
依赖倒置原则(Dependence Inversion Principle,DIP),原始定义包含三层含义:高层模块不应该依赖低层模块,两者都应该依赖其抽象;抽象不应该依赖细节;细节应该依赖抽象。
比如:有一个奔驰类,在person类中调用其方法可以实现驾驶奔驰,但却无法驾驶宝马,所以最好的办法是写一个汽车接口,这样可以让不同品牌的汽车来实现它,person类中就可以通过调用实现好的类来驾驶不同汽车。
五、接口隔离原则:
接口隔离原则的定义是客户端不应该依赖他不需要的接口。
比如:一个work接口中有teach和study两个抽象方法,而对于teacher来说只用teach方法,却也要把study方法实现一遍,这样代码就会冗余,并增加程序运行负担,因此应该把teach和study方法分别写成两个接口。这样可以提高代码的灵活性。
六、迪米特原则:
迪米特原则也被称为最小知识原则,他的定义一个对象应该对其他对象保持最小的了解。简单的理解就是高内聚,低耦合,一个类尽量减少对其他对象的依赖,并且这个类的方法和属性能用私有的就尽量私有化.
java访问修饰符
| 访问修饰符 | 本类 | 同包 | 子类 | 其他 |
|---|---|---|---|---|
| private | √ | |||
| 默认 | √ | √ | ||
| protected | √ | √ | √ | |
| public | √ | √ | √ | √ |
java变量
变量定义:
[访问修饰符] [修饰符] 数据类型 变量名 [=赋值]
注:“=”并不是数学中的“等号”,而是一个赋值运算符
注:变量的值指向基本数据类型时就是直接指向那个值,例如int a=1,就是定义了int类型的变量a,它的值为1;而当变量指向引用类型时,它的值指向则是那个引用类型在内存中地址,例如Student st=new Student()就是定义了一个变量st,它的值指向了new出来的对象 Student()的地址,然而,java是屏蔽指针的,不能直接获取到内存地址,只能通过hashCode()方法,hashCode()它返回的是根据内部地址转化成一个整数,但并不代表内存地址。假设你直接输出st,也就是输出指向对象的变量,它默认就会调用Object的toString方法,toString方法是输出类的包名,类名以及hashCode值,当然,可以通过重写toString方法来改变变量的输出。
命名规范:
变量的定义必须严格按照标识符的命名规则,即0~9数字、字母、下滑线、$等组成,且首字母不能是数字、不能是java关键字。
·首字母必须小写,当有多个单词组成时,后面的单词首字母要大写。
·变量名一般由名词组成,区分大小写,没有长度限制。
变量类型:
参考:https://blog.csdn.net/hmxz2nn/article/details/81271878
局部变量:类的方法中的变量。 实例变量:独立于方法之外的变量,没有static修饰。 类变量:独立于方法之外的变量,用static修饰。
局部变量 局部变量有以下特性:
1.局部变量声明在方法、构造方法或者语句块中; 2.局部变量在方法、构造方法、或者语句块被执行的时候创建,当它们执行完成后,变量将会被销毁; 3.访问修饰符和static不能用于局部变量,final可以; 4.局部变量只在声明它的方法、构造方法或者语句块中可见; 5.局部变量是在栈上分配的。 6.局部变量没有默认值,所以局部变量被声明后,必须经过初始化,才可以使用(不使用的话如果不初始化也不会报错)。
实例变量 实例变量有以下特性:
1.实例变量声明在一个类中,但在方法、构造方法和语句块之外; 2.当一个对象被实例化之后,每个实例变量的值就跟着确定; 3.具有默认初始值,数值型变量默认值是0,布尔型默认值是false,引用类型默认值是null。变量的值可以在声明的时候指定,也可以在构造方法中指定。 4.实例变量在对象创建的时候创建,在对象被销毁的时候销毁,其存在于对象所在的堆内存中; 5.实例变量的值应该至少被一个方法、构造方法或者语句块引用,使得外部能够通过这些方式获取实例变量信息; 6.实例变量可以声明在使用前或者使用后; 7.访问修饰符可以修饰实例变量; 8.实例变量对于类中的方法、构造方法或者语句块是可见的。一般情况下应该把实例变量设为私有。通过使用访问修饰符可以使实例变量对子类可见; 9.变量的值可以在声明时指定,也可以在构造方法中指定;
类变量(静态变量)
静态变量的存储位置,参考:https://blog.csdn.net/x_iya/article/details/81260154 https://blog.csdn.net/xu_jl1997/article/details/89433916
类变量也称为静态变量,在类中以static关键字声明,但必须在构造方法和语句块之外。 类变量有以下特性:
1.无论一个类创建了多少个对象,类只拥有类变量的一份拷贝。 2.静态变量除了被声明为常量外很少使用。常量是指声明为public/private,final和static类型的变量。常量初始化后不可改变。 3.jdk8之前静态变量储存在方法区的静态存储区,jdk8之后static 成员变量位于 Class对象内。经常被声明为常量,很少单独使用static声明变量。 4.静态变量在第一次被访问时创建,在程序结束时销毁。 5.与实例变量具有相似的可见性。但为了对类的使用者可见,大多数静态变量声明为public类型。 6.默认值和实例变量相似。数值型变量默认值是0,布尔型默认值是false,引用类型默认值是null。变量的值可以在声明的时候指定,也可以在构造方法中指定。此外,静态变量还可以在静态语句块中初始化。 7.静态变量可以通过:ClassName(类名).VariableName(变量名)的方式访问。 8.类变量被声明为public static final类型时,类变量名称一般建议使用大写字母。如果静态变量不是public和final类型,其命名方式与实例变量以及局部变量的命名方式一致。
数据类型
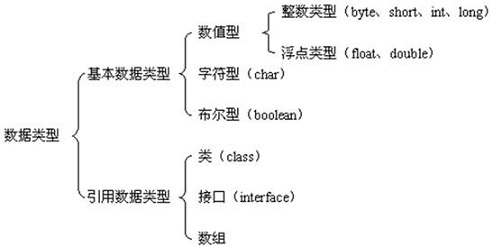
基本数据类型变量存的是数据本身,而引用类型变量存的是保存数据的空间地址。说白了,基本数据类型变量里存储的是直接放在抽屉里的东西,而引用数据类型变量里存储的是这个抽屉的钥匙,钥匙和抽屉一一对应。
String 是一种常见的引用数据类型,用来表示字符串。在程序开发中,很多操作都要使用字符串来完成,例如系统中的用户名、密码、电子邮箱等。
基本数据类型
Java 中一共八种基本数据类型,下表列出了基本数据类型的数据范围、存储格式、默认值、包装类型等。
| 数据类型 | 默认值 | 存储格式 | 数据范围 | 包装类型 |
|---|---|---|---|---|
| short | 0 | 2 个字节 | -32,768 到 32767 | Short |
| int | 0 | 4 个字节 | -2,147,483,648 到 2,147,483,647 | Integer |
| byte | 0 | 1 个字节 | -128 到 127 | Byte |
| char | 空 | 2 个字节 | Unicode 的字符范围:’\u0000’(即为 0)到’\uffff’(即为 65,535) | Character |
| long | 0L 或 0l | 8 个字节 | -9,223,372,036,854,775,808 到 9,223,372,036, 854,775,807 | Long |
| float | 0.0F 或 0.0f | 4 个字节 | 32 位 IEEEE-754 单精度范围 | Float |
| double | 0.0 或 0.0D(d) | 8 个字节 | 64 位 IEEE-754 双精度范围 | Double |
| boolean | false | 1 位 | true 或 false | Boolean |
Switch支持的数据类型
jdk1.5前:
- 基本数据类型:byte, short, char, int
jdk1.5后,对四个包装类的支持是因为java编译器在底层手动进行拆箱,而对枚举类的支持是因为枚举类有一个ordinal方法,该方法实际上是一个int类型的数值。
- 包装数据类型:Byte, Short, Character, Integer
- 枚举类型:Enum
JDK1.7开始支持String类型,但实际上String类型有一个hashCode算法,结果也是int类型。而byte short char类型可以在不损失精度的情况下向上转型成int类型。所以总的来说,可以认为switch中只支持int。
- 字符串类型:String(Jdk 7+(JDK1.7之后) 开始支持
方法传递参数原则:
假设传的是基本数据,传递是值传递,也就是拷贝一份传进去
假设是引用传递,就是传地址,并将局部变量指向该地址,假设修改了此地址中的值,那原先指向该相同地址的引用的值也是这个新的值(因为指向同一块地址)。【注意,除了String和包装类之外的其他引用类型,包括字符串数组,List集合类等等,他们赋新值都是直接赋值,而String和包装类是新建一个,所以不会影响原先的值】
例子:
【提前说明一个特殊例子(此处不贴代码了,所以提前说明):当传引用类型时,进入方法的时候是把方法中的变量指向和传值的变量相同的内存地址,假设此时在方法中将该局部变量引用指向别的地方,那这个变量的引用就再也不是指向传进来的那个变量的地址了,在这个方法中两者再无瓜葛(类似于下面第三个例子)】
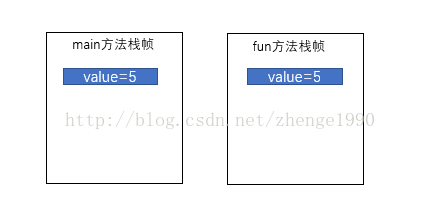
传递基本类型,会拷贝值public class Test {public static void main(String[] args) {int a = 5;fun(a);System.out.println(a);// 输出结果为5}private static void fun(int a) {a += 1;}}
图例:
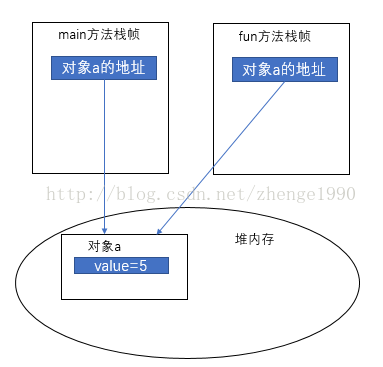
xxxxxxxxxx//2、引用类型传递的例子public class Test {public static void main(String[] args) {A a = new A(5);fun(a);System.out.println(a.a);// 输出结果为6}private static void fun(A a) {a.a += 1;}static class A {public int a;public A(int a) {this.a = a;}}}
原理图例:
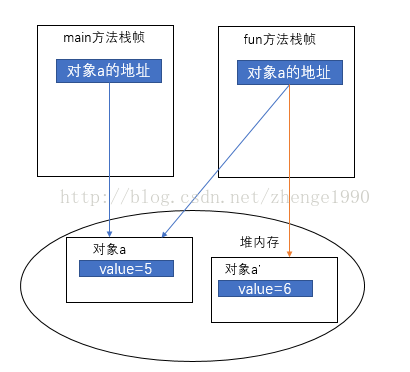
xxxxxxxxxx//3、特殊情况,String和包装类,String底层是不可变的数组,每次改变值都是重新新建数组,包装类也是新建一个类出来所以他们虽然传的是引用,但是赋值的时候是新建而不是改变原有内容的值public class Test {public static void main(String[] args) {Integer a = 5;String str="aaa";fun(a,str);System.out.println(a);// 输出结果为5System.out.println(str);// 输出结果为aaa}private static void fun(Integer a,String str) {a += 1;str="bbb";}}
图例:
整数
byte、short、int、long 四种基本数据类型表示整数,需要注意的是 long 类型,使用 long 修饰的变量需要在数值后面加上 L 或者 l,比如long num=1L;,一般使用大写 L,为了避免小写 l 与数值 1 混淆。
浮点数
float 和 double 类型表示浮点数,即可以表示小数部分。需要注意的是 float 类型的数值后面需要加上 F 或者 f,否则会被当成 double 类型处理。double 类型的数值可以加上 D 或 d,也可以不加。
char 类型
char 类型用于表示单个字符。需要将字符用单引号括起来char a='a',char 可以和整数互相转换,如果字符a也可以写成char a=97。也可以用十六进制表示char a = '\u0061'。
boolean 类型
boolean 类型(布尔类型)用于表示真值true或者假值false,Java 中布尔值不能和整数类型或者其它类型互相转换。
常量
常量是不可改变的量,一次赋值,永不改变 。
常量定义:常量需要有final修饰符修饰。常量声明时必须初始化。常量标识符必须大写,且多个单词时用下滑线连接。
注意:有时候常量也可以不用在声明时就初始化。
eg:做局部变量
public class Test {
public static void main(String[] args)
{
final int Y;
Y=9;
}}
做静态全局变量时,若声明时不服初值,必须在静态代码块中赋初值。
static final int Y;
static{
Y=9;}
做非静态全局变量时,若声明时不服初值,则必须在非静态代码块中赋值。
数组
数组是在内存中存储相同数据类型的连续的空间
【注意:数组定义也是遵循变量的各种规则的,不过数组分配空间后会自动赋初值,基础类型赋0,引用类型赋null,所以length的值一直都是数组的空间大小,比如int a[]=int[4],length为4;所以如果要统计数组中自己赋值的个数,只能通过遍历自己计算】
声明一个数组就是在内存空间中划出一串连续的空间,数组名代表的是连续空间的首地址,通过首地址可以依次访问数组所有元素,元素在数组中的排序叫做下标从零开始
数组是类吗
是的。数组是Object的子类,只不过数组是特殊的对象,类型不是程序员可见的,当我们获取数组的类名称输出的时候,例子:
test_array [] ta=new test_array[4]; System.out.println(ta.getClass().getName());
输出结果是:[Ltest_array; [ 表示是一维数组(两个就是二维) ,L 表示是对象类型,后面是类名。
如果是基础类型,例如整形数组,则输出例子为:[I ,I表示int基础类型。
【(未论证)注意:数组在new时开辟了一段连续的空间,如果是基础类型则存的是值。如果是引用类型,则存的是引用对象的地址。】
创建数组
1、先声明,后分配空间,再赋值
声明数组:数据类型[] 数组名 或者 数据类型 数组名[];数组名遵循也就是变量名。 数据类型可以是任意类型,可以是int,也可以是String,也可以是自定义的类
分配空间:数组名=new 数据类型 [ 数组长度 ],例如整合上一步:Student[] st=new Student[5];
赋值:例如:st[4]=... 注意是从0开始的,不能越界
2、直接创建,整合以上三步
方式一:int[] scores={ 78,91,84 }:创建一个长度为4的整形数组
方式二:int[] scores=new int [ ] { 78,91,84 }:此处[ ]不能指定长度
循环操作java数组:
注意:java为数组提供了唯一一个属性length,数组是Java特殊处理过的,数组的length即不是方法,也不是字段。 在一个数组对象上调用length,会被Java编译器编译成一条arraylength指令(Java binary code)。 而访问字段的语句会被编译成getfield或getstatic指令,调用方法的语句则会被编译成invokestatic,invokevirtual或invokespecial等指令。参考:https://blog.csdn.net/jayzym/article/details/76643527

使用foreach遍历
foreach 并不是 Java 中的关键字,是 for 语句的特殊简化版本,在遍历数组、集合时, foreach 更简单便捷。从英文字面意思理解 foreach 也就是“ for 每一个”的意思

数组扩容
三种方式:
① int[] arr2=new int[arr1.length*2] //新数组长度
xfor(int i=0;i<arr1.length;i++){ //复制arr2[i]=arr1[i];}
② int[] arr2=java.util.Arrays.copyOf(原数组名,新数组长度);
③ int[] arr2=new int[arr1.length*2] System.arraycopy(原数组名,起始下标,新数组名,起始下标,复制长度);
二维数组
与一维的定义类似
1、 声明数组并分配空间
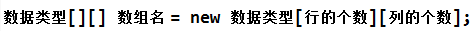
或者

如:

2、 赋值
二维数组的赋值,和一维数组类似,可以通过下标来逐个赋值,注意索引从 0 开始
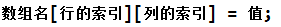
也可以在声明数组的同时为其赋值
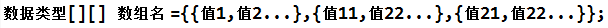
如:

Arrays类
Arrays 类是 Java 中提供的一个工具类,在 java.util 包中。该类中包含了一些方法用来直接操作数组,比如可直接实现数组的排序、搜索等
常用的有:
排序: Arrays.sort(数组名),用后数组的序列会被改变
转化成字符串:**Arrays.toString(数组名);**该方法按顺序把多个数组元素连接在一起,多个元素之间使用逗号和空格隔开
转化成List:Arrays.asList(数组名),转化成一个List集合,不过如果数组的类型是基础类型的话会把内容全部看成一个字段,而如果是非基础类型(如包装类),那就会转成List,这个list和List类还不太一样,这个list不能append和remove;
Arrays.binarySearch//二分查找 Arrays.copyOf //复制 Arrays.copyOfRange//复制部分 Arrays.fill//填充 Arrays.hashCode//哈希值
length,length(),size()的区别
在java语言中,数组提供了length属性来获取数组的长度;
length()方法是针对字符串而言的,String、StringBuffer、StringBuilder提供length()方法来计算字符串的长度【注意java和c语言不一样,字符串没有以\0结尾,字符的个数就是字符串长度】;
size方法是针对Collection和Map而言的,用于查看集合中有多少元素,默认为0。
位运算符
Java 定义了位运算符,应用于整数类型(int),长整型(long),短整型(short),字符型(char),和字节型(byte)等类型。位运算时先转换为二进制,再按位运算。
表格中的例子中,变量a的值为 60(00111100),变量b(00001101)的值为 13:
| 位运算符 | 名称 | 描述 | 举例 |
|---|---|---|---|
| & | 按位与 | 如果相对应位都是 1,则结果为 1,否则为 0 | (a&b),得到 12,即 0000 1100 |
| 丨 | 按位或 | 如果相对应位都是 0,则结果为 0,否则为 1 | ( a 丨 b )得到 61,即 0011 1101 |
| ^ | 按位异或 | 如果相对应位值相同,则结果为 0,否则为 1 | (a^b)得到 49,即 0011 0001 |
| ~ | 按位补 | 翻转操作数的每一位,即 0 变成 1,1 变成 0 | (〜a)得到-61,即 1100 0011 |
| << | 按位左移 | 左操作数按位左移右操作数指定的位数 | a<<2 得到 240,即 1111 0000 |
| >> | 按位右移 | 左操作数按位右移右操作数指定的位数 | a>>2 得到 15 即 1111 |
| >>> | 按位右移补零 | 左操作数的值按右操作数指定的位数右移,移动得到的空位以零填充 | a>>>2 得到 15 即 0000 1111 |
逻辑运算符
逻辑运算符是通过运算符将操作数或等式进行逻辑判断的语句。
表格中的例子中,假设布尔变量 a 为真,变量 b 为假:
| 逻辑运算符 | 名称 | 描述 | 类型 | 举例 |
|---|---|---|---|---|
| && | 与 | 当且仅当两个操作数都为真,条件才为真 | 双目运算符 | (a && b)为假 |
| || | 或 | 两个操作数任何一个为真,条件为真 | 双目运算符 | (a || b)为真 |
| ! | 非 | 用来反转操作数的逻辑状态。如果条件为真,则逻辑非运算符将得到假 | 单目运算符 | (!a)为假 |
| ^ | 异或 | 如果两个操作数逻辑相同,则结果为假,否则为真 | 双目运算符 | (a ^ b)为真 |
当使用&&(与)逻辑运算符时,在两个操作数都为 true 时,结果才为 true,但是当得到第一个操作为 false 时,其结果就必定是 false,这时候就不会再判断第二个操作了。
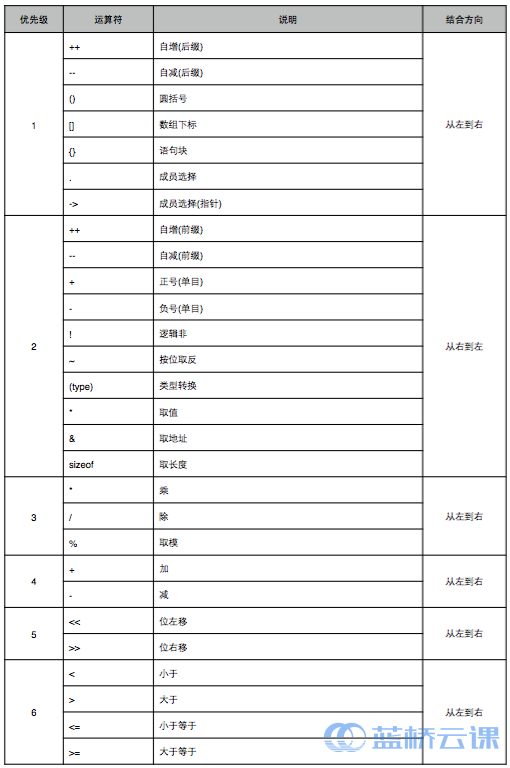
运算符优先级
运算符的优先级是帮助我们在一个表达式中如何对于不同的运算符和相同的运算符,进行正确的运算顺序。
运算符的优先级不需要特别地去记忆它,比较复杂的表达式一般使用圆括号()分开,提高可读性。
!
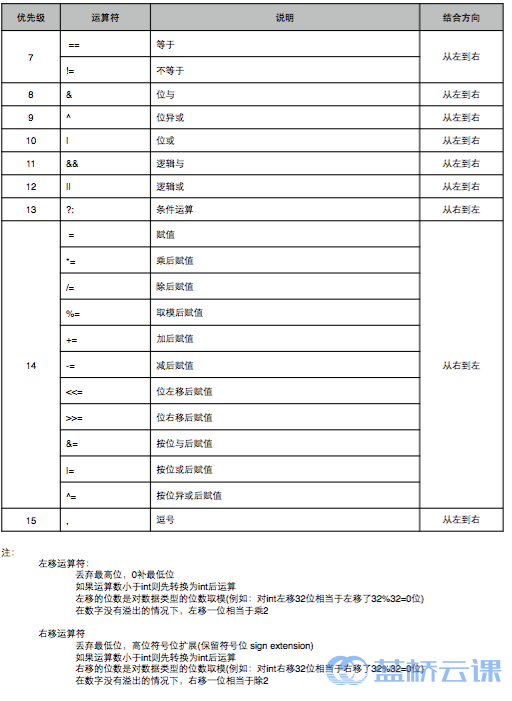
泛型
xxxxxxxxxxpublic class Box<T> {// T stands for "Type"private T t;public void set(T t) { this.t = t; }public T get() { return t; }}
Java中的泛型是什么 ? 使用泛型的好处是什么?
【概括:避免了强转,提供了编译期的类型安全】这是在各种Java泛型面试中,一开场你就会被问到的问题中的一个,主要集中在初级和中级面试中。那些拥有Java1.4或更早版本的开发背景的人都知道,在集合中存储对象并在使用前进行类型转换是多么的不方便。泛型防止了那种情况的发生。它提供了编译期的类型安全,确保你只能把正确类型的对象放入集合中,避免了在运行时出现ClassCastException。
Java的泛型是如何工作的 ? 什么是类型擦除 ?
【在运行时擦出了类型的相关信息】泛型是通过类型擦除来实现的,编译器在编译时擦除了所有类型相关的信息,所以在运行时不存在任何类型相关的信息。例如List
什么是泛型中的限定通配符和非限定通配符 ?
限定通配符对类型进行了限制。有两种限定通配符,一种是它通过确保类型必须是T的子类来设定类型的上界,另一种是它通过确保类型必须是T的父类来设定类型的下界。泛型类型必须用限定内的类型来进行初始化,否则会导致编译错误。另一方面**表示了非限定通配符**,因为<?>可以用任意类型来替代。
java开发——为什么要使用泛型?用Object不行吗?
答案是可以的!也就是说泛型可以实现的功能,用Object也是可以实现的。
那为什么还要使用泛型呢?因为泛型有如下优点:
1、无须类型强转,提高效率,避免了强转出错。
2、通配符"?"的使用提高了程序的阅读性。
3、限制通配符(<? extends T>、<? super T>)提高了程序的健壮性。
static
Java 中的 static 使用之静态变量
Java 中被 static 修饰的成员称为静态成员或类成员。它属于整个类所有,而不是某个对象所有,即被类的所有对象所共享。静态成员可以使用类名直接访问,也可以使用对象名进行访问。当然,鉴于他作用的特殊性更推荐用类名访问~~【注意static不能修饰局部变量】
使用 static 可以修饰变量、方法和代码块。
例如,我们在类中定义了一个 静态变量 hobby ,操作代码如下所示:

运行结果:
注意:静态成员属于整个类,当系统第一次使用该类时,就会为其分配内存空间直到该类被卸载才会进行资源回收!~~
Java 中的 static 使用之静态方法
与静态变量一样,我们也可以使用 static 修饰方法,称为静态方法或类方法。其实之前我们一直写的 main 方法就是静态方法。静态方法的使用如:

运行结果:
需要注意:
1、 静态方法中可以直接调用同类中的静态成员,但不能直接调用非静态成员。如:

如果希望在静态方法中调用非静态变量,可以通过创建类的对象,然后通过对象来访问非静态变量。如:

2、 在普通成员方法中,则可以直接访问同类的非静态变量和静态变量,如下所示:

3、 静态方法中不能直接调用非静态方法,需要通过对象来访问非静态方法。如:

Java 中的 static 使用之静态初始化块
Java 中可以通过初始化块进行数据赋值。如:

在类的声明中,可以包含多个初始化块,当创建类的实例时,就会依次执行这些代码块。如果使用 static 修饰初始化块,就称为静态初始化块。
需要特别注意:静态初始化块只在类加载时执行,且只会执行一次,同时静态初始化块只能给静态变量赋值,不能初始化普通的成员变量。
我们来看一段代码:
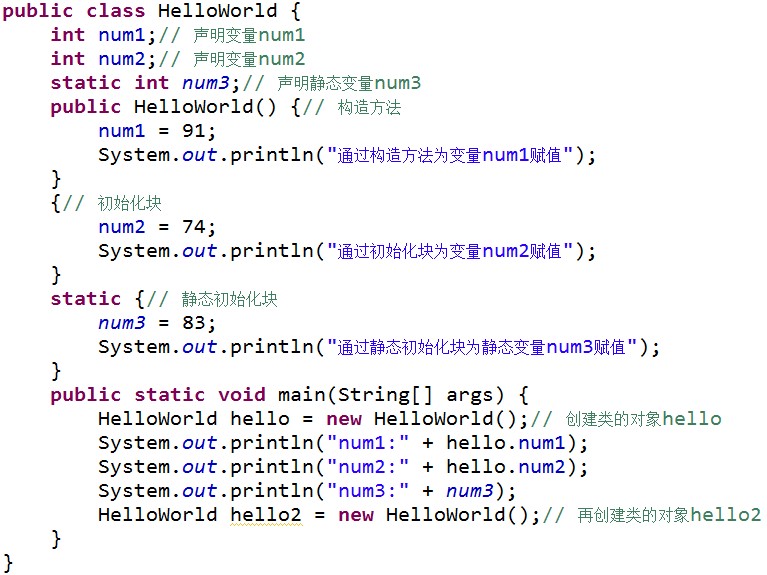
运行结果:

通过输出结果,我们可以看到,程序运行时静态初始化块最先被执行,然后执行普通初始化块,最后才执行构造方法。由于静态初始化块只在类加载时执行一次,所以当再次创建对象 hello2 时并未执行静态初始化块。
java在创建对象时候 成员的执行顺序
https://blog.csdn.net/u013749540/article/details/78632537
Ø 父类中的静态成员和静态初始化块,按照在代码中出现的顺序依次执行。
Ø 子类静态成员和静态初始化代码块,按照在代码中出现的顺序依次执行。
Ø 父类实例成员和实例初始化块,按照在代码中出现的顺序依次执行。(创建每一个实例对象的时候都执行)
Ø 执行父类的构造方法。(创建每一个实例对象的时候都执行)
Ø 子类实例成员和实例初始化块,按照在代码中出现的顺序依次执行。(创建每一个实例对象的时候都执行)
Ø 执行子类构造方法。(创建每一个实例对象的时候都执行)
注意:静态代码块只执行一次,在类被加载到内存中初始化的时候执行,不一定需要创建对象才触发。
final关键字
final可以修饰类、方法、属性和变量
final修饰类时
则该类不允许被继承,注意 final类中的所有成员方法都会被隐式地指定为final方法。
final修饰方法时
则改方法不允许被覆盖(重写),当方法的修饰符不是private时,子类不能出现相同的方法,如果修饰符既有private和final时【其实就是private】,子类可以出现相同方法,此时不是重写父类的方法,而是子类自己定义的一个新方法。【注:类的private方法会隐式地被指定为final方法。】
final修饰变量时
分两种情况:
修饰基本数据类型的变量:那么再也不能改变该值的值了;即为常量。
修饰引用类型的变量:该变量存的是一个内存地址,该变量的地址就不能变了,但是该内存地址所指向的那个对象还是可以变的,(就像你记住了人家的门牌号,但你不能管人家家里人员数量)【String和包装类不能变,因为他们不会改变值,赋值时只会new一个然后把引用指向新的那边,此时引用被改动了,所以不行】
例如:
final修饰变量时的赋值问题:
使用final时,变量不会进行隐式自动初始化,当改变量是类的实例变量时,必须在定义时就赋值或在构造方法中赋值(只能选其一)【如果定义时没赋值那么构造函数必须赋值,且每一个构造函数都要赋值,当然,值可以是不一样的,不同构造函数new出来的变量值可以是不一样的】,当改变量是类的局部变量时(方法里的变量),那在定义时就必须赋值。
关于final和static
final和static并没有实际关系,static是针对class对象的修饰符,是类级别的,重点强调唯一性,而final是针对普通对象的,重点强调不可修改性。
当一个类属性定义时被static和final同时修饰【static不能修饰局部变量,final可以】,且赋予确定值时(不通过随机数等来赋值),此时称变量为编译期常量,在类的加载时,运行到准备阶段static修饰的变量会被赋予初值,但是编译期常量会被特殊处理,赋予代码中正确的值,此时如果类还没初始化,该值就被读出,此时不会触发初始化,因为值本身就是正确的了。详细可以参考博客:https://blog.nowcoder.net/n/67a8d9210f4347d5ba35462e7dd1a87a
什么是 Java 中的内部类
问:什么是内部类呢?
答:内部类( Inner Class )就是定义在另外一个类里面的类。与之对应,包含内部类的类被称为外部类。
问:那为什么要将一个类定义在另一个类里面呢?清清爽爽的独立的一个类多好啊!!
答:内部类的主要作用如下:
- 内部类提供了更好的封装,可以把内部类隐藏在外部类之内,不允许同一个包中的其他类访问该类
- 内部类的方法可以直接访问外部类的所有数据,包括私有的数据
- 内部类所实现的功能使用外部类同样可以实现,只是有时使用内部类更方便
问:内部类有几种呢?
答:内部类可分为以下几种:
- 成员内部类
- 静态内部类
- 方法内部类
- 匿名内部类
Java 中的成员内部类
内部类中最常见的就是成员内部类,也称为普通内部类。我们来看如下代码:

运行结果为:
从上面的代码中我们可以看到,成员内部类的使用方法:
1、 Inner 类定义在 Outer 类的内部,相当于 Outer 类的一个成员变量的位置,Inner 类可以使用任意访问控制符,如 public 、 protected 、 private 等
2、 Inner 类中定义的 test() 方法可以直接访问 Outer 类中的数据,而不受访问控制符的影响,如直接访问 Outer 类中的私有属性a
3、 定义了成员内部类后,必须使用外部类对象来创建内部类对象,而不能直接去 new 一个内部类对象,即:内部类 对象名 = 外部类对象.new 内部类( );
4、 编译上面的程序后,会发现产生了两个 .class 文件
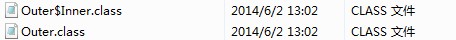
其中,第二个是外部类的 .class 文件,第一个是内部类的 .class 文件,即成员内部类的 .class 文件总是这样:外部类名$内部类名.class
另外,友情提示哦:
1、 外部类是不能直接使用内部类的成员和方法滴

可先创建内部类的对象,然后通过内部类的对象来访问其成员变量和方法。
2、 如果外部类和内部类具有相同的成员变量或方法,内部类默认访问自己的成员变量或方法,如果要访问外部类的成员变量,可以使用 this 关键字。如:

运行结果:
Java 中的静态内部类
静态内部类是 static 修饰的内部类,这种内部类的特点是:
1、 静态内部类不能直接访问外部类的非静态成员,但可以通过 new 外部类().成员 的方式访问
2、 如果外部类的静态成员与内部类的成员名称相同,可通过“类名.静态成员”访问外部类的静态成员;如果外部类的静态成员与内部类的成员名称不相同,则可通过“成员名”直接调用外部类的静态成员
3、 创建静态内部类的对象时,不需要外部类的对象,可以直接创建 内部类 对象名= new 内部类();

运行结果 : 
Java 中的方法内部类
方法内部类就是内部类定义在外部类的方法中,方法内部类只在该方法的内部可见,即只在该方法内可以使用。

一定要注意哦:由于方法内部类不能在外部类的方法以外的地方使用,因此方法内部类不能使用访问控制符和 static 修饰符。
引用类型转换
1.向上类型转换(隐式/自动类型转换),是小类型到大类型的转换
2.向下类型转换(强制类型转换),是大类型到小类型
3.instanceof运算符(判断前面是否包含后面),来解决引用对象的类型,避免类型转换的安全性问题
接口interface
必选加sbstract关键字,默认有加
接口可以多继承父类,但类只能单继承 一个类可以实现一个或多个接口
常量:接口中的属性是常量,即使定义时不添加public static final修饰符,系统也会自动加上 方法:只能是抽象方法,不加public static修饰符,系统也会自动加上
匿名内部类
没有名字的内部类,一般不关注类的名称只关注实现
语法:
Interface i=new Interface(){
public void method(){...};
}
i.method
Java API 简介
Java 的核心 API 是非常庞大的,这给开发者来说带来了很大的方便。所谓的 API 就是一些已经写好、可直接调用的类库。Java 里有非常庞大的 API,其中有一些类库是我们必须得掌握的,只有熟练掌握了 Java 一些核心的 API,我们才能更好的使用 Java。
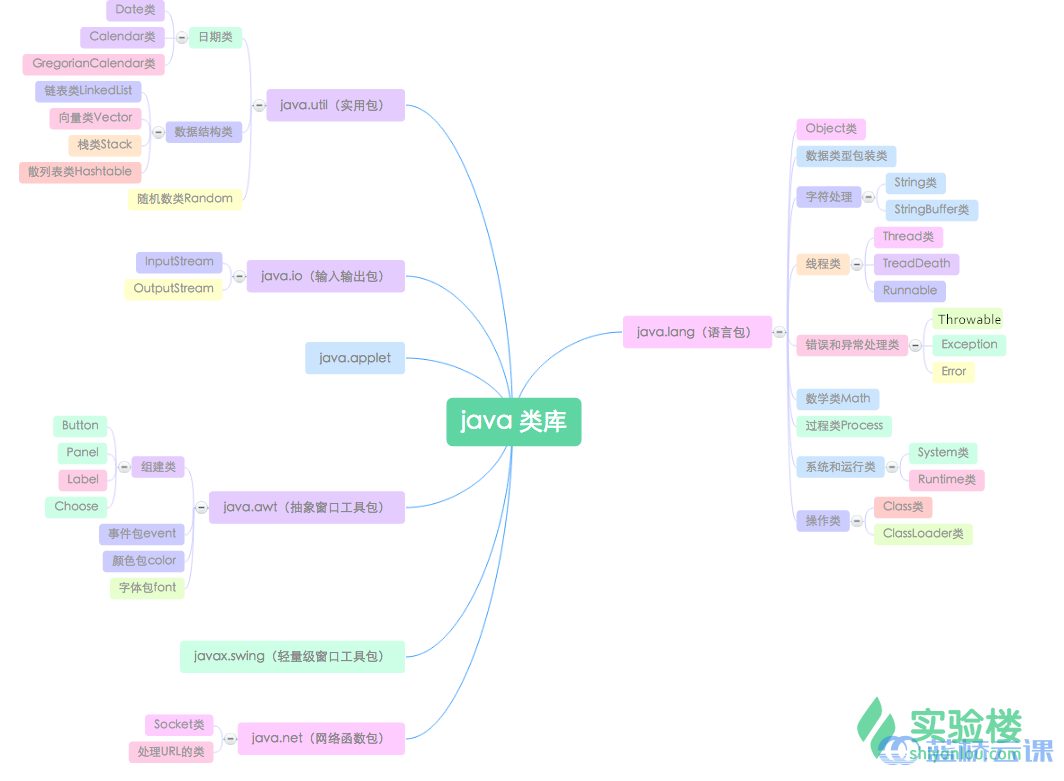
java.lang 包
| 原始数据类型 | 包装类 |
|---|---|
| byte(字节) | Byte |
| char(字符) | Character |
| int(整型) | Integer |
| long (长整型) | Long |
| float(浮点型) | Float |
| double (双精度) | Double |
| boolean (布尔) | Boolean |
| short(短整型) | Short |
一、String
String 对象创建后则不能被修改,是不可变的,所谓的修改其实是创建了新的对象,所指向的内存空间不同。
【String的底层是通过封装一个字符数组来实现的,它重写了Object中的很多方法,比如toString(),原先是返回对象的类型和hashCode,被改成返回String的值了,还有hashCode()方法也改了,改成返回ASCII值,其他方法待考察】
0.java中String new和直接赋值的区别
xxxxxxxxxx对于字符串:其对象的引用都是存储在栈中的,如果是编译期已经创建好(直接用双引号定义的)的就存储在堆中的字符串常量池中,如果是运行期(new出来的)才能确定的就存储在堆中的运行时常量池。对于equals相等的字符串,在常量池中永远只有一份,在堆中有多份。
例如:
String str1="ABC"; 和String str2 = new String("ABC");
String str1="ABC" 可能创建一个对象或者不创建对象,如果"ABC"这个字符串在java String池里不存在,会在java String池创建这个一个String对象("ABC").如果已经存在,str1直接reference to 这个String池里的对象。
String str2 = new String("ABC") 至少创建一个对象,也可能两个。因为用到new 关键字,会在heap创建一个 str2 的String 对象,它的value 是 "ABC".同时,如果"ABC"这个字符串在java String池里不存在,会在java String池创建这个一个String对象("ABC").
String 有一个intern() 方法,native,用来检测在String pool是否已经有这个String存在。
考虑下面的问题:
String str1 = new String("ABC"); String str2 = new String("ABC");
str1 == str2 的值是True 还是False呢? False.
String str3 = "ABC"; String str4 = "ABC";
String str5 = "A" + "BC";
str3 == str4 的值是True 还是False呢? True.
str3 == str5 的值是True 还是False呢? True.
String a = "ABC"; String b="AB"; String c=b+"C"; System.out.println(a==c); false a和b都是字符串常量所以在编译期就被确定了!
而c中有个b是引用不是字符串常量所以不会在编译期确定。 而String是final的!所以在b+"c"的时候实际上是新创建了一个对象,然后在把新创建对象的引用传给c.
xxxxxxxxxxpublic static void main(String[] args) throws Exception {String a = "b" ;String b = "b" ;System.out.println( a == b);String d = new String( "d" ).intern() ; //如果吧new和intern拆分成两条语句那结果就是false,intern返回的是常量池中的引用,如果不赋值那还是引用堆中的;除非是d=new String(“d”)+new String(“d”);此时再调用d.intern,在jdk6之前是复制d对象成副本放到常量池中,jdk6之后则直接将堆中的引用放到常量池中,此时如果有字符串“dd”,他指向的是常量池中“dd”的堆对象的引用,这时候d就和“dd”地址一样了。String c = "d" ;System.out.println( c == d); //System.out.println("------------------");String d1 = new String( "d" ) ;String e1=d1.intern();String c1 = "d" ;System.out.println( c1 == d1);System.out.println( c1 == e1);System.out.println( e1 == d1);System.out.println("------------------");String s1=new String("kvill");String s2=s1.intern();System.out.println( s1==s2 ); //s1=s1.intern()System.out.println( s1+" "+s2 );System.out.println( s2==s1.intern() );}
运行结果: true true false true false false kvill kvill true
s1==s1.intern()为false说明原来的“kvill”仍然存在;
例子代码:
xxxxxxxxxxString s1 = "china";String s2 = "china";String s3 = "china";String ss1 = new String("china");String ss2 = new String("china");String ss3 = new String("china");这里解释一下,对于通过 new 产生一个字符串(假设为 ”china” )时,会先去常量池中查找是否已经有了 ”china” 对象,如果没有则在常量池中创建一个此字符串对象,然后堆中再创建一个常量池中此 ”china” 对象的拷贝对象。
也就是有道面试题: String s = new String(“xyz”); 产生几个对象?
一个或两个。如果常量池中原来没有 ”xyz”, 就是两个。如果原来的常量池中存在“xyz”时,就是一个。
对于基础类型的变量和常量:变量和引用存储在栈中,常量存储在常量池中。
应用的情况:建议在平时的使用中,尽量使用String = “abcd”;这种方式来创建字符串,而不是String = new String(“abcd”);这种形式,因为使用new构造器创建字符串对象一定会开辟一个新的heap(堆)空间,而双引号则是采用了String interning(字符串驻留)进行了优化,效率比构造器高。
1.Java 中 String 类的常用方法 Ⅰ
String 类提供了许多用来处理字符串的方法,例如,获取字符串长度、对字符串进行截取、将字符串转换为大写或小写、字符串分割等,下面我们就来领略它的强大之处吧。
String 类的常用方法:
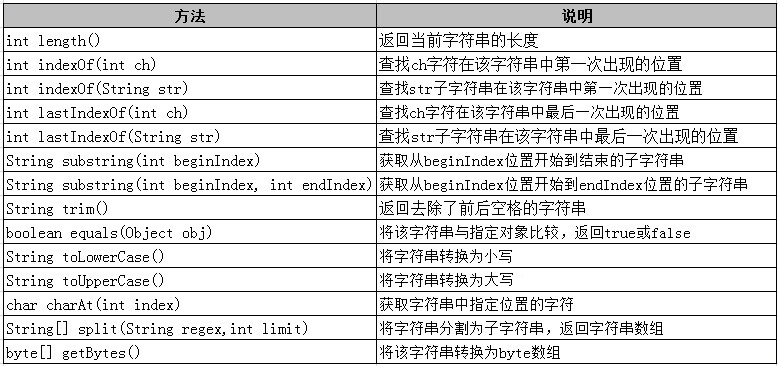
xxxxxxxxxx`equalsIgnoreCase()`方法,其用法与 equals 一致,不过它会忽视大小写。字符串连接有两种方法:1.使用`+`,比如`String s = "Hello " + "World!"`使用`+`进行连接,不仅可以连接字符串,也可以连接其他类型。但是要求进行连接时至少有一个参与连接的内容是字符串类型。2.使用 String 类的 concat() 方法
结合代码来熟悉一下方法的使用:(JAVA前后有两个空格)

运行结果:

友情提示:
\1. 字符串 str 中字符的索引从0开始,范围为 0 到 str.length()-1
\2. 使用 indexOf 进行字符或字符串查找时,如果匹配返回位置索引;如果没有匹配结果,返回 -1
\3. 使用 substring(beginIndex , endIndex) 进行字符串截取时,包括 beginIndex 位置的字符,不包括 endIndex 位置的字符
2.Java 中的 String 类常用方法 Ⅱ
我们继续来看 String 类常用的方法,如下代码所示:

运行结果:

那么,“==” 和 equals() 有什么区别呢? ==: 判断两个字符串在内存中首地址是否相同,即判断是否是同一个字符串对象 equals(): 比较存储在两个字符串对象中的内容是否一致
PS:字节是计算机存储信息的基本单位,1 个字节等于 8 位, gbk 编码中 1 个汉字字符存储需要 2 个字节,1 个英文字符存储需要 1 个字节。所以我们看到上面的程序运行结果中,每个汉字对应两个字节值,如“学”对应 “-47 -89” ,而英文字母 “J” 对应 “74” 。同时,我们还发现汉字对应的字节值为负数,原因在于每个字节是 8 位,最大值不能超过 127,而汉字转换为字节后超过 127,如果超过就会溢出,以负数的形式显示。
3.java中字符串和字符数组的转换?
1、字符串是类,字符数组是数组。 2、字符数组是char类型的,字符串是String类型的 3、两者之间的相互转化: String s="this is a string"; char[ ] c={'t','h','i','s','i','s','a','c','h','a','r'}; 字符串转换为字符数组 char[ ] ch=s.toCharArray(); 字符数组转化为字符串 String str=string.valueOf(c);
4.StringBuilder 和StringBuffer
当频繁操作字符串时,就会额外产生很多临时变量。使用 StringBuilder 或 StringBuffer 就可以避免这个问题。至于 StringBuilder 和StringBuffer ,它们基本相似,不同之处,StringBuffer 是线程安全的,而 StringBuilder 则没有实现线程安全功能,所以性能略高。因此一般情况下,如果需要创建一个内容可变的字符串对象,应优先考虑使用 StringBuilder 类。
StringBuffer
| 构造方法 | 说明 |
|---|---|
| StringBuffer() | 构造一个其中不带字符的字符串缓冲区,其初始容量为 16 个字符 |
| StringBuffer(CharSequence seq) | 构造一个字符串缓冲区,它包含与指定的 CharSequence 相同的字符 |
| StringBuffer(int capacity) | 构造一个不带字符,但具有指定初始容量的字符串缓冲区 |
| StringBuffer(String str) | 构造一个字符串缓冲区,并将其内容初始化为指定的字符串内容 |
StringBuffer 类的常用方法:
| 方法 | 返回值 | 功能描述 |
|---|---|---|
| insert(int offsetm,Object s) | StringBuffer | 在 offsetm 的位置插入字符串 s |
| append(Object s) | StringBuffer | 在字符串末尾追加字符串 s |
| length() | int | 确定 StringBuffer 对象的长度 |
| setCharAt(int pos,char ch) | void | 使用 ch 指定的新值设置 pos 指定的位置上的字符 |
| toString() | String | 转换为字符串形式 |
| reverse() | StringBuffer | 反转字符串 |
| delete(int start, int end) | StringBuffer | 删除调用对象中从 start 位置开始直到 end 指定的索引(end-1)位置的字符序列 |
| replace(int start, int end, String s) | StringBuffer | 使用一组字符替换另一组字符。将用替换字符串从 start 指定的位置开始替换,直到 end 指定的位置结束 |
StringBuilder
StringBuilder 类提供了很多方法来操作字符串:
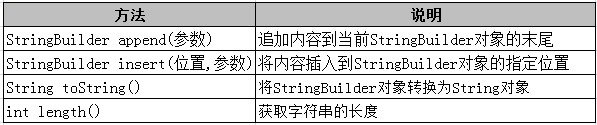
例如:在下面的示例代码中,创建了 StringBuilder 对象,用来存储字符串,并对其做了追加和插入操作。这些操作修改了 str 对象的值,而没有创建新的对象,这就是 StringBuilder 和 String 最大的区别。

运行结果: 
Java 中基本类型和字符串之间的转换
在程序开发中,我们经常需要在基本数据类型和字符串之间进行转换。
其中,基本类型转换为字符串有三种方法:
\1. 使用包装类的 toString() 方法
\2. 使用String类的 valueOf() 方法
\3. 用一个空字符串加上基本类型,得到的就是基本类型数据对应的字符串

再来看,将字符串转换成基本类型有两种方法:
\1. 调用包装类的 parseXxx 静态方法
\2. 调用包装类的 valueOf() 方法转换为基本类型的包装类,会自动拆箱

valueOf与parseInt方法
首先从返回类型可以看出parseInt返回的是基本类型int,而valueOf返回的是对象(可自动拆装箱)。
源码:
public static Integer valueOf(String s) throws NumberFormatException {
return Integer.valueOf(parseInt(s, 10));
}
public static Integer valueOf(int i) {
assert IntegerCache.high >= 127;
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
public static int parseInt(String s) throws NumberFormatException {
return parseInt(s,10);
}
因为JDK5以后实现了自动拆装箱,因而两者的差别也不是特别大了,但是从效率上考虑,建议首先考虑parseInt方法。
二、包装类
1.Integer 类
java.lang 包中的 Integer 类、Long 类和 Short 类都是 Number 的子类,他们的区别在于不同子类里面封装着不同的数据类型,比如 Integer 类包装了一个基本类型 int。其包含的方法基本相同。
| 方法 | 返回值 | 功能描述 |
|---|---|---|
| byteValue() | byte | 以 byte 类型返回该 Integer 的值 |
| compareTo(Integer anotherInteger) | int | 在数字上比较 Integer 对象。如果这两个值相等,则返回 0;如果调用对象的数值小于 anotherInteger 的数值,则返回负值;如果调用对象的数值大于 anotherInteger 的数值,则返回正值 |
| equals(Object IntegerObj) | boolean | 比较此对象与指定对象是否相等 |
| intValue() | int | 以 int 型返回此 Integer 对象 |
| shortValue() | short | 以 short 型返回此 Integer 对象 |
| longValue() | long | 以 long 型返回此 Integer 对象 |
| floatValue() | float | 以 float 型返回此 Integer 对象 |
| doubleValue() | double | 以 double 型返回此 Integer 对象 |
| toString() | String | 返回一个表示该 Integer 值的 String 对象 |
| valueOf(String str) | Integer | 返回保存指定的 String 值的 Integer 对象 |
| parseInt(String str) | int | 将字符串参数作为有符号的十进制整数进行解析 |
| parseInt(String str,int radix) | int | 实现将字符串按照参数 radix 指定的进制转换为十进制 |
2.Character 类
Character 类型的对象包含类型为 char 的单个字段。
| 方法 | 返回值 | 说明 |
|---|---|---|
| isDigit(char ch) | boolean | 确定字符是否为数字 |
| isLetter(char ch) | boolean | 确定字符是否为字母 |
| isLowerCase(char ch) | boolean | 确定字符是否为小写字母 |
| isUpperCase(char ch) | boolean | 确定字符是否为大写字母 |
| isWhitespace(char ch) | boolean | 确定字符是否为空白字符 |
| isUnicodeIdentifierStart(char ch) | boolean | 确定是否允许将指定字符作为 Unicode 标识符中的首字符 |
3.Boolean 类
一个 Boolean 类型的对象只包含一个类型为 boolean 的字段。
Boolean 类的构造方法也有两个:
- Boolean(boolean value),创建一个表示 value 参数的 Boolean 对象,如
Boolean b = new Boolean(true) - Boolean(String s),如果 String 参数不为 null 且在忽略大小写时等于 "true",创建一个表示 true 值的 Boolean 对象,如
Boolean b = new Boolean("ok"),为 false。
| 方法 | 返回值 | 说明 |
|---|---|---|
| booleanValue() | boolean | 将 Boolean 对象的值以对应的 boolean 值返回 |
| equals(Object obj) | boolean | 判断调用该方法的对象与 obj 是否相等。当且仅当参数不是 null,而且与调用该方法的对象一样都表示同一个 boolean 值的 Boolean 对象时,才返回 true |
| parseBoolean(String s) | boolean | 将字符串参数解析为 boolean 值 |
| toString() | String | 返回表示该 boolean 值的 String 对象 |
| valueOf(String s) | Boolean | 返回一个用指定得字符串表示值的 boolean 值 |
三、Math
| 方法 | 返回值 | 功能描述 |
|---|---|---|
| sin(double numvalue) | double | 计算角 numvalue 的正弦值 |
| cos(double numvalue) | double | 计算角 numvalue 的余弦值 |
| acos(double numvalue) | double | 计算 numvalue 的反余弦 |
| asin(double numvalue) | double | 计算 numvalue 的反正弦 |
| atan(double numvalue) | double | 计算 numvalue 的反正切 |
| pow(double a, double b) | double | 计算 a 的 b 次方 |
| sqrt(double numvalue) | double | 计算给定值的正平方根 |
| abs(int numvalue) | int | 计算 int 类型值 numvalue 的绝对值,也接收 long、float 和 double 类型的参数 |
| ceil(double numvalue) | double | 返回大于等于 numvalue 的最小整数值 |
| floor(double numvalue) | double | 返回小于等于 numvalue 的最大整数值 |
| max(int a, int b) | int | 返回 int 型 a 和 b 中的较大值,也接收 long、float 和 double 类型的参数 |
| min(int a, int b) | int | 返回 a 和 b 中的较小值,也可接受 long、float 和 double 类型的参数 |
| rint(double numvalue) | double | 返回最接近 numvalue 的整数值 |
| round(T arg) | arg 为 double 时返回 long,为 float 时返回 int | 返回最接近 arg 的整数值 |
| random() | double | 返回带正号的 double 值,该值大于等于 0.0 且小于 1.0 |
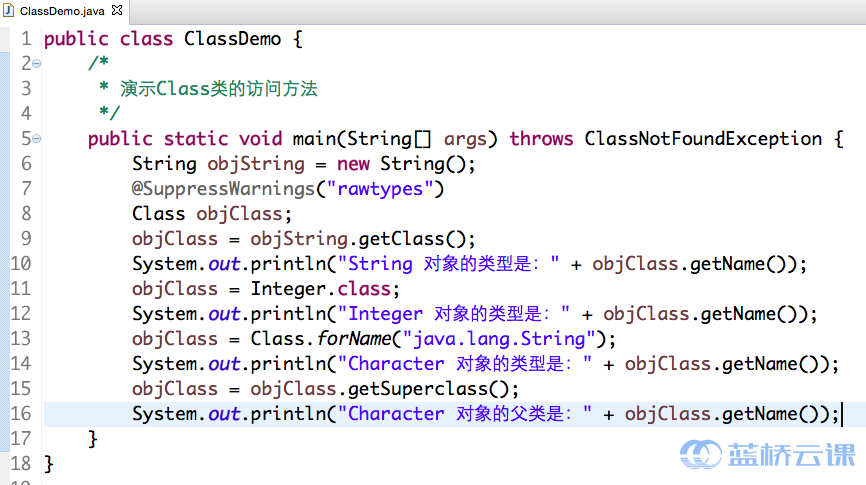
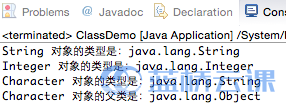
四、类 Class
Class 类的实例表示正在运行的 Java 应用程序中的类或接口。在 Java 中,每个 Class 都有一个相应的 Class 对象,即每一个类,在生成的.class文件中,就会产生一个 Class 对象,用于表示这个类的类型信息。我们获取 Class 实例有三种方法:
- 利用对象调用 `getClass()`方法获取该对象的 Class 实例
- 使用 Class 类的静态方法 `forName(String className)`,用类的名字获取一个 Class 实例
- 运用
**.class的方式来获取 Class 实例**,对于基本数据类型的封装类,还可以采用.TYPE来获取相对应的基本数据类型的 Class 实例
class 类没有共有的构造方法,它由 JVM 自动调用。
五、反射
反射可以提供运行时的类信息,并且这个类可以在运行时才加载进来,甚至在编译时期该类的 .class 不存在也可以加载进来。
Class 和 java.lang.reflect 一起对反射提供了支持,java.lang.reflect 类库主要包含了以下三个类:
- Field :可以使用 get() 和 set() 方法读取和修改 Field 对象关联的字段;
- Method :可以使用 invoke() 方法调用与 Method 对象关联的方法;
- Constructor :可以用 Constructor 创建新的对象。
xxxxxxxxxxpublic class Apple {private int price;public int getPrice() {return price;}public void setPrice(int price) {this.price = price;}public static void main(String[] args) throws Exception{//正常的调用Apple apple = new Apple();apple.setPrice(5);System.out.println("Apple Price:" + apple.getPrice());//使用反射调用Class clz = Class.forName("com.chenshuyi.api.Apple");Method setPriceMethod = clz.getMethod("setPrice", int.class);Constructor appleConstructor = clz.getConstructor();Object appleObj = appleConstructor.newInstance();setPriceMethod.invoke(appleObj, 14);Method getPriceMethod = clz.getMethod("getPrice");System.out.println("Apple Price:" + getPriceMethod.invoke(appleObj));}}结果:Apple Price:5Apple Price:14
反射的优点:
- 可扩展性 :应用程序可以利用全限定名创建可扩展对象的实例,来使用来自外部的用户自定义类。
- 类浏览器和可视化开发环境 :一个类浏览器需要可以枚举类的成员。可视化开发环境(如 IDE)可以从利用反射中可用的类型信息中受益,以帮助程序员编写正确的代码。
- 调试器和测试工具 : 调试器需要能够检查一个类里的私有成员。测试工具可以利用反射来自动地调用类里定义的可被发现的 API 定义,以确保一组测试中有较高的代码覆盖率。
反射的缺点:
尽管反射非常强大,但也不能滥用。如果一个功能可以不用反射完成,那么最好就不用。在我们使用反射技术时,下面几条内容应该牢记于心。
- 性能开销 :反射涉及了动态类型的解析,所以 JVM 无法对这些代码进行优化。因此,反射操作的效率要比那些非反射操作低得多。我们应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。
- 安全限制 :使用反射技术要求程序必须在一个没有安全限制的环境中运行。如果一个程序必须在有安全限制的环境中运行,如 Applet,那么这就是个问题了。
- 内部暴露 :由于反射允许代码执行一些在正常情况下不被允许的操作(比如访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用,这可能导致代码功能失调并破坏可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化。
六、注解Annotation
https://www.cnblogs.com/acm-bingzi/p/javaAnnotation.html
注解其实就是代码中的特殊标记,这些标记可以在编译、类加载、运行时被读取,并执行相对应的处理。
Java注解是附加在代码中的一些元信息,用于一些工具在编译、运行时进行解析和使用,起到说明、配置的功能。注解不会也不能影响代码的实际逻辑,仅仅起到辅助性的作用。包含在 java.lang.annotation 包中。
带成员变量的注解:
xxxxxxxxxxpublic @interface MyAnnotation {//interface加一个@//定义了两个成员变量String username() default "";int age();}
注意:在注解上定义的成员变量只能是String、数组、Class、枚举类、注解
注解的用处:
1、生成文档。这是最常见的,也是java 最早提供的注解。常用的有@param @return 等 2、跟踪代码依赖性,实现替代配置文件功能。比如Dagger 2 依赖注入 3、在编译时进行格式检查。如@override 放在方法前,如果你这个方法并不是覆盖了超类方法,则编译时就能检查出。
注解的原理:
注解本质是一个继承了Annotation 的特殊接口,其具体实现类是Java 运行时生成的动态代理类。而我们通过反射获取注解时,返回的是Java 运行时生成的动态代理对象$Proxy1。通过代理对象调用自定义注解(接口)的方法,会最终调用AnnotationInvocationHandler 的invoke 方法。该方法会从memberValues 这个Map 中索引出对应的值。而memberValues 的来源是Java 常量池。
元注解:
https://www.cnblogs.com/acm-bingzi/p/javaAnnotation.html
java.lang.annotation 提供了四种元注解,专门注解其他的注解(在自定义注解的时候,需要使用到元注解): @Documented – 注解是否将包含在JavaDoc中 @Retention – 什么时候使用该注解 @Target – 注解用于什么地方 @Inherited – 是否允许子类继承该注解
常见标准的Annotation:
1.)Override java.lang.Override 是一个标记类型注解,它被用作标注方法。它说明了被标注的方法重载了父类的方法,起到了断言的作用。如果我们使用了这种注解在一个没有覆盖父类方法的方法时,java 编译器将以一个编译错误来警示。 2.)Deprecated Deprecated 也是一种标记类型注解。当一个类型或者类型成员使用@Deprecated 修饰的话,编译器将不鼓励使用这个被标注的程序元素。所以使用这种修饰具有一定的“延续性”:如果我们在代码中通过继承或者覆盖的方式使用了这个过时的类型或者成员,虽然继承或者覆盖后的类型或者成员并不是被声明为@Deprecated,但编译器仍然要报警。 3.)SuppressWarnings SuppressWarning 不是一个标记类型注解。它有一个类型为String[] 的成员,这个成员的值为被禁止的警告名。对于javac 编译器来讲,被-Xlint 选项有效的警告名也同样对@SuppressWarings 有效,同时编译器忽略掉无法识别的警告名。 @SuppressWarnings("unchecked")
七、Object类
| 方法 | 返回值 | 功能描述 |
|---|---|---|
| equals(Objectobj) | boolean | 将当前对象实例与给定的对象进行比较,检查它们是否相等 |
| finalize() throws Throwable | void | 当垃圾回收器确定不存在对象的更多引用时,由对象的垃圾回收器调用此方法。通常被子类重写 |
| getClass() | Class | 返回当前对象的 Class 对象 |
| toString() | String | 返回此对象的字符串表示 |
| wait() throws InterruptedException | void | 在其他线程调用此对象的 notify() 方法或 notifyAll() 方法前,使当前线程进入等待状态 |
toString()方法
在Object类里面定义toString()方法的时候返回的对象在哈希code码(对象地址字符串)
可以通过重写toString()方法表示出对象的属性
equals和==的区别
==是一个比较运算符,基本数据类型比较的是值,引用数据类型比较的是地址值。
equals()是一个方法,只能比较引用数据类型。重写前比较的是地址值,重写后比一般是比较对象的属性。
除了String和封装器,equals()和“==”没什么区别 但String和封装器重写了equals(),所以在这里面,equals()指比较字符串或封装对象对应的原始值是否相等,"=="是比较两个对象是否为同一个对象
java日期和随机数
学习 java.util 中的 Date 类、Calendar 类,Random 类以及 java.time 包中的 LocalTime 类。
一、java.util 和 java.time 包介绍
java.util 包提供了一些实用的方法和数据结构。比如日期类 Date,日历类 Calendar 以及随机数类 Random,同时包里还提供了 collection 框架,像堆栈 Stack、向量 Vector、位集合 Bitset 以及哈希表 Hashtable 等表示数据结构的类。而 java.time 包是 java8 新提供的包,里面对时间和日期提供了新的 api,弥补了 java.util 包对日期和时间操作的不足。
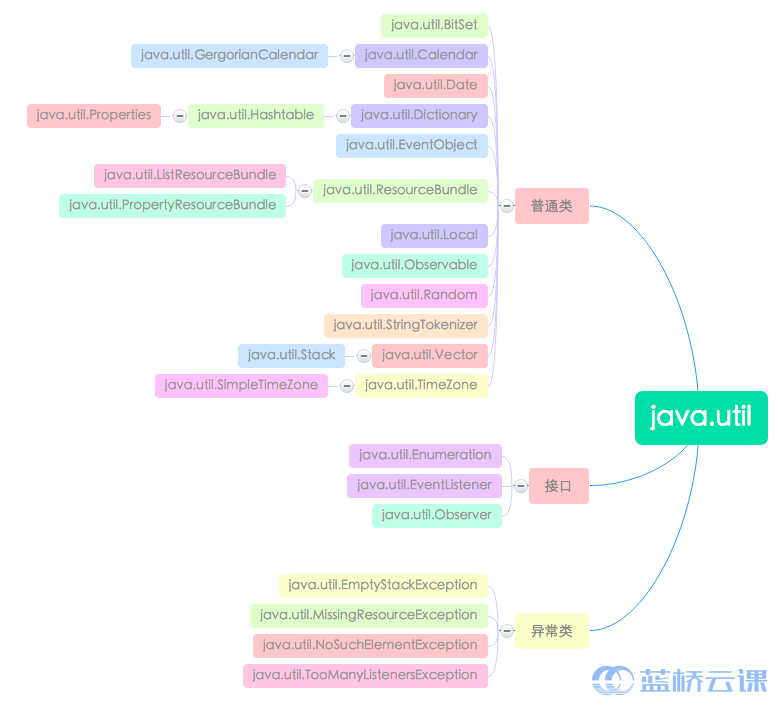
本次课程主要介绍 Date 类、Calendar 类、Random 类以及 LocalTime 类的相关知识,其他 collection 框架等方面的内容将在后面的课程进行介绍。
二、Date 类和Calendar 类
链接:https://www.shiyanlou.com/courses/109/labs/1119/document/#2.4%20java.time%20包
Date 类表示日期和时间,里面封装了操作日期和时间的方法。Date 类经常用来获取系统当前时间。
我们来看看类 Date 中定义的未过时的构造方法:
| 构造方法 | 说明 |
|---|---|
| Date() | 构造一个 Date 对象并对其进行初始化以反映当前时间 |
| Date(long date) | 构造一个 Date 对象,并根据相对于 GMT 1970 年 1 月 1 日 00:00:00 的毫秒数对其进行初始化 |
###
在早期的 JDK 版本中,Date 类附有两大功能:
- 允许用年、月、日、时、分、秒来解释日期
- 允许对表示日期的字符串进行格式化和句法分析
在 JDK1.1 中提供了类 Calendar 来完成第一种功能,类 DateFormat 来完成第二项功能。DateFormat 是 java.text 包中的一个类。与 Date 类有所不同的是,DateFormat 类可以接受用各种语言和不同习惯表示的日期字符串。
但是 Calendar 类是一个抽象类,它完成 Date 类与普通日期表示法之间的转换,而我们更多的是使用 Calendar 类的子类 GregorianCalendar 类。它实现了世界上普遍使用的公历系统。当然我们也可以继承 Calendar 类,然后自己定义实现日历方法。
三、java.time 包
因为 java8 之前的日期和时间 api 饱受诟病,比如线程安全问题,比如 Date 的月份是从 0 开始的!而 java.time 包中将月份封装成为了枚举类型。
首先了解一下 LocalTime 类,LocalTime 类是一个不可变类(也就是用 final 修饰的类),和 String 类一样,所以它是线程安全的。除了 LocalTime 还有 LocalDate(日期)、LocalDateTime(日期和时间)等,他们的使用方式都差不多。
初始化例子:LocalDateTime currentTime = LocalDateTime.now();
Java8的DateTimeFormatter是线程安全的,而SimpleDateFormat并不是线程安全。
DateTimeFormatter可以用来格式化输出日期时间
四、Random 类
Java 实用工具类库中的类 java.util.Random 提供了产生各种类型随机数的方法。它可以产生 int、long、float、double 以及 Gaussian 等类型的随机数。这也是它与 java.lang.Math 中的方法 Random() 最大的不同之处,后者只产生 double 型的随机数。
| 构造方法 | 说明 |
|---|---|
| Random() | 产生一个随机数需要基值,这里将系统时间作为 seed |
| Random(long seed) | 使用单个 long 种子创建一个新的随机数生成器 |
强调:种子数只是随机算法的起源数字,和生成的随机数字的区间无关。相同种子数的Random对象,相同次数生成的随机数字是完全相同的。
普通方法原型:
xxxxxxxxxx//该方法是设定基值seedpublic synchronized void setSeed(long seed)//该方法是产生一个整型随机数public int nextInt()//该方法是产生一个long型随机数public long nextLong()//该方法是产生一个Float型随机数public float nextFloat()//该方法是产生一个Double型随机数public double nextDouble()//该方法是产生一个double型的Gaussian随机数public synchronized double nextGaussian()/*synchronized 是 Java 语言的关键字,当它用来修饰一个方法或者一个代码块的时候,能够保证在同一时刻最多只有一个线程执行该段代码*/
例子:
1、生成[0,10]区间的整数
int n3 = r.nextInt(11);
相对于整数区间,[0,10]区间和[0,11)区间等价,所以即生成[0,11)区间的整数。
2、生成[-3,15)区间的整数
int n4 = r.nextInt(18) - 3;
Java 集合框架
一、Collection 接口

它也是 List、Set 和 Queue 接口的父接口。Collection 接口中定义了可用于操作 List、Set 和 Queue 的方法——增删改查。
| 方法 | 返回值 | 说明 |
|---|---|---|
| add(E e) | boolean | 向 collection 的尾部追加指定的元素(可选操作) |
| addAll(Collection<? extend E> c) | boolean | 将指定 collection 中的所有元素都添加到此 collection 中(可选操作) |
| clear() | void | 移除此 collection 中的所有元素(可选操作) |
| contains(Object o) | boolean | 如果此 collection 包含指定的元素,则返回 true |
| containsAll(Collection<?> c) | boolean | 如果此 collection 包含指定 collection 的所有元素,则返回 true |
| equals(Object o) | boolean | 比较此 collection 与指定对象是否相等 |
| hashCode() | int | 返回此 collection 的哈希码值 |
| isEmpty() | boolean | 如果此 collection 不包含元素,则返回 true |
| iterator() | Iterator | 返回在此 collection 的元素上进行迭代的迭代器 |
| remove(Object o) | boolean | 移除此 collection 中出现的首个指定元素(可选操作) |
| removeAll(Collection<?> c) | boolean | 移除此 collection 中那些也包含在指定 collection 中的所有元素(可选操作) |
| retainAll(Collection<?> c) | boolean | 仅保留此 collection 中那些也包含在指定 collection 的元素(可选操作) |
| size() | int | 返回此 collection 中的元素数 |
| toArray() | Object[] | 返回包含此 collection 中所有元素的数组 |
| toArray(T[] a) | 返回包含此 collection 中所有元素的数组;返回数组的运行时类型与指定数组的运行时类型相同 |
二、Map接口

TreeMap:基于红黑树实现。 HashMap:基于哈希表实现。 HashTable:和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程可以同时写入 HashTable 并且不会导致数据不一致。它是遗留类,不应该去使用它。现在可以使用 ConcurrentHashMap 来支持线程安全,并且 ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。 LinkedHashMap:使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
Map 接口也是一个非常重要的集合接口,用于存储键/值对。Map 中的元素都是成对出现的,键值对就像数组的索引与数组的内容的关系一样,将一个键映射到一个值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。我们可以通过键去找到相应的值。
value 可以存储任意类型的对象,我们可以根据 key 键快速查找 value。Map 中的键/值对以 Entry 类型的对象实例形式存在。
| 方法 | 返回值 | 说明 |
|---|---|---|
| clear() | void | 从此映射中移除所用映射关系(可选操作) |
| containsKey(Object key) | boolean | 如果此映射包含指定键的映射关系,则返回 true |
| containsValue(Object value) | boolean | 如果此映射将一个或多个键映射到指定值,则返回 true |
| entrySet() | Set<Map.Entry<K,V>> | 返回此映射中包含的映射关系的 Set 视图 |
| equals(Object o) | boolean | 比较指定的对象与此映射是否相等 |
| get(Object key) | V | 返回指定键所映射的值;如果此映射不包含该键的映射关系,则返回 null |
| hashCode() | int | 返回此映射的哈希码值 |
| isEmpty() | boolean | 如果此映射未包含键-值映射关系,则返回 true |
| keySet() | Set | 返回此映射中包含的键的 Set 视图 |
| put(K key, V value) | V | 将指定的值与此映射中的指定键关联(可选操作) |
| putAll(Map<? extends K, ? extends V> m) | void | 从指定映射中将所有映射关系复制到此映射中(可选操作) |
| remove(Object key) | V | 如果存在一个键的映射关系,则将其从此映射中移除(可选操作) |
| size | int | 返回此映射中的键-值映射关系数 |
| values() | Collection | 返回此映射中包含的值的 Collection 视图 |
三、List 接口与 ArrayList 类
List 是一个接口,不能实例化,需要一个具体类来实现实例化。List 集合中的对象按照一定的顺序排放,里面的内容可以重复。 List 接口实现的类有:ArrayList(实现动态数组),Vector(实现动态数组),LinkedList(实现链表),Stack(实现堆栈)。
List ArrayList:基于动态数组实现,支持随机访问。 Vector:和 ArrayList 类似,但它是线程安全的。 LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此, LinkedList 还可以用作栈、队列和双向队列**
List 在 Collection 基础上增加的方法:
| 方法 | 返回值 | 说明 |
|---|---|---|
| add(int index, E element) | void | 在列表的指定位置插入指定元素(可选操作) |
| addAll(int index, Collection<? extends E> c) | boolean | 将指定 collection 中的所有元素都插入到列表中的指定位置(可选操作) |
| get(int index) | E | 返回列表中指定位置的元素 |
| indexOf(Object o) | int | 返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1 |
| lastIndexOf(Object o) | int | 返回此列表中最后出现的指定元素的索引;如果列表不包含此元素,则返回 -1 |
| listIterator() | ListIterator | 返回此列表元素的列表迭代器(按适当顺序) |
| listIterator(int index) | ListIterator | 返回此列表元素的列表迭代器(按适当顺序),从列表的指定位置开始 |
| remove(int index) | E | 移除列表中指定位置的元素(可选操作) |
| set(int index, E element) | E | 用指定元素替换列表中指定位置的元素(可选操作) |
| subList(int fromIndex, int toIndex) | List | 返回列表中指定的 fromIndex(包括 )和 toIndex(不包括)之间的部分视图 |
定义时可以通过List
ArrayList 类实现一个可增长的动态数组,它可以存储不同类型的对象,而数组则只能存放特定数据类型的值。
Arrays 类, Arrays 包含用来操作数组(比如排序和搜索)的各种方法,asList() 方法用来返回一个受指定数组支持的固定大小的列表。
List 有两种基本的类型,除了 ArrayList 外,还有 LinkedList,LinkedList 类用于创建链表数据结构,两者的对比如下:
- ArrayList:它擅长于随机访问元素,但是插入和移除元素时较慢。
- LinkedList(链表):它通过代价较低的在 List 中进行插入和删除操作,提供了优化的顺序访问,它在随机访问方面相对较慢,但是它的特性集较 ArrayList 更大。
四、Set 接口和 HashSet 类
Set 接口也是 Collection 接口的子接口,它有一个很重要也是很常用的实现类——HashSet,Set 是元素无序并且不包含重复元素的 collection(List 可以重复),被称为集。
Set TreeSet:基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。 HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说 使用 Iterator 遍历 HashSet 得到的结果是不确定的。 LinkedHashSet:具有 HashSet 的查找效率,且内部使用双向链表维护元素的插入顺序。
HashSet 由哈希表(实际上是一个 HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。
Set与List的不同,由于无序,所以不提供set()方法get()方法等
Set里遍历元素只能用foreach 和 iterator
五、Quere接口
Queue LinkedList:可以用它来实现双向队列。 PriorityQueue:基于堆结构实现,可以用它来实现优先队列。
五、HashSet和HashMap的区别
| HashMap | HashSet |
|---|---|
| HashMap实现了Map接口 | HashSet实现了Set接口 |
| HashMap储存键值对 | HashSet仅仅存储对象 |
| 使用put()方法将元素放入map中 | 使用add()方法将元素放入set中 |
| HashMap中使用键对象来计算hashcode值 | HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false |
| HashMap比较快,因为是使用唯一的键来获取对象 | HashSet较HashMap来说比较慢 |
HashSet底层通过包装HashMap来实现(适配器模式),HashSet在添加一个值的时候,实际上是将此值作为HashMap中的key来进行保存。
六、HashMap 类
HashMap 是基于哈希表的 Map 接口的一个重要实现类。HashMap 中的 Entry (键值对)对象是无序排列的,Key 值和 value 值都可以为 null,但是一个 HashMap 只能有一个 key 值为 null 的映射。
1、key 值不可重复,value可以 2、每个键最多只能映射到一个值 3、支持泛型,如Map<K,V> 4、提供了返回key集合【keySet()】,value集合【values()】以及Entry(键值对)【entrySet()】集合的方法
- 底层数组+链表实现,可以存储null键和null值,线程不安全
- 初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂
- 扩容针对整个Map,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入
- 插入元素后才判断该不该扩容,有可能无效扩容(插入后如果扩容,如果没有再次插入,就会产生无效扩容)
- 当Map中元素总数超过Entry数组的75%,触发扩容操作,为了减少链表长度,元素分配更均匀
- 计算index方法:index = hash & (tab.length – 1)
HashMap:基于哈希表实现。使用HashMap要求添加的键类明确定义了hashCode()和equals()[可以重写hashCode()和equals()],为了优化HashMap空间的使用,您可以调优初始容量和负载因子。
HashMap的初始值还要考虑加载因子:
- 哈希冲突:若干Key的哈希值按数组大小取模后,如果落在同一个数组下标上,将组成一条Entry链,对Key的查找需要遍历Entry链上的每个元素执行equals()比较。
- 加载因子:为了降低哈希冲突的概率,默认当HashMap中的键值对达到数组大小的75%时,即会触发扩容。因此,如果预估容量是100,即需要设定100/0.75=134的数组大小。
- *空间换时间:如果希望加快Key查找的时间,还可以进一步降低加载因子,加大初始大小,以降低哈希冲突的概率。*
TreeMap:基于红黑树实现。所有的元素都保持着某种固定的顺序。TreeMap没有调优选项,因为该树总处于平衡状态。
七、HashTable
Hashtable和HashMap都实现了Map接口,但是Hashtable的实现是基于Dictionary抽象类的。Java5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
- 底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化
- 初始size为11,扩容:newsize = olesize*2+1
- 计算index的方法:index = (hash & 0x7FFFFFFF) % tab.length
八、ConcurrentHashMap的实现——JDK7版本
https://www.liangzl.com/get-article-detail-28344.html
https://blog.csdn.net/bill_xiang_/article/details/81122044
1.1 分段锁机制
ConcurrentHashMap采用了分段锁的设计,只有在同一个分段内才存在竞态关系,不同的分段锁之间没有锁竞争。相比于对整个Map加锁的设计,分段锁大大的提高了高并发环境下的处理能力。但同时,由于不是对整个Map加锁,导致一些需要扫描整个Map的方法(如size(), containsValue())需要使用特殊的实现,另外一些方法(如clear())甚至放弃了对一致性的要求(ConcurrentHashMap是弱一致性的,具体请查看ConcurrentHashMap能完全替代HashTable吗?)。
Hashtable之所以效率低下主要是因为其实现使用了synchronized关键字对put等操作进行加锁,而synchronized关键字加锁是对整个对象进行加锁,也就是说在进行put等修改Hash表的操作时,锁住了整个Hash表,从而使得其表现的效率低下;因此,在JDK1.5~1.7版本,Java使用了分段锁机制实现ConcurrentHashMap.
ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap(JDK7与JDK8中HashMap的实现)的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表;同时又是一个ReentrantLock(Segment继承了ReentrantLock)。ConcurrentHashMap中的HashEntry相对于HashMap中的Entry有一定的差异性:HashEntry中的value以及next都被volatile修饰,这样在多线程读写过程中能够保持它们的可见性,代码如下:
xxxxxxxxxxstatic final class HashEntry<K,V> {final int hash;final K key;volatile V value;volatile HashEntry<K,V> next;
并发度(Concurrency Level)
并发度可以理解为程序运行时能够同时更新ConccurentHashMap且不产生锁竞争的最大线程数,实际上就是ConcurrentHashMap中的分段锁个数,即Segment[]的数组长度。ConcurrentHashMap默认的并发度为16,但用户也可以在构造函数中设置并发度。。
如果并发度设置的过小,会带来严重的锁竞争问题;如果并发度设置的过大,原本位于同一个Segment内的访问会扩散到不同的Segment中,CPU cache命中率会下降,从而引起程序性能下降。(文档的说法是根据你并发的线程数量决定,太多会导性能降低)
九、JDK8中的ConcurrentHashMap
https://www.liangzl.com/get-article-detail-28344.html
ConcurrentHashMap在JDK8中进行了巨大改动,很需要通过源码来再次学习下Doug Lea的实现方法。
它摒弃了Segment(锁段)的概念,而是启用了一种全新的方式实现,利用CAS算法。它沿用了与它同时期的HashMap版本的思想,底层依然由“数组”+链表+红黑树的方式思想(JDK7与JDK8中HashMap的实现),但是为了做到并发,又增加了很多辅助的类,例如TreeBin,Traverser等对象内部类。
十、ConcurrentHashMap总结
JDK6,7中的ConcurrentHashmap主要使用Segment来实现减小锁粒度,把HashMap分割成若干个Segment,在put的时候需要锁住Segment,get时候不加锁,使用volatile来保证可见性,当要统计全局时(比如size),首先会尝试多次计算modcount来确定,这几次尝试中,是否有其他线程进行了修改操作,如果没有,则直接返回size。如果有,则需要依次锁住所有的Segment来计算。
jdk7中ConcurrentHashmap中,当长度过长碰撞会很频繁,链表的增改删查操作都会消耗很长的时间,影响性能,所以jdk8 中完全重写了concurrentHashmap,代码量从原来的1000多行变成了 6000多 行,实现上也和原来的分段式存储有很大的区别。
主要设计上的变化有以下几点:
- 不采用segment而采用node,锁住node来实现减小锁粒度。
- 设计了MOVED状态 当resize的中过程中 线程2还在put数据,线程2会帮助resize。
- 使用3个CAS操作来确保node的一些操作的原子性,这种方式代替了锁。
- sizeCtl的不同值来代表不同含义,起到了控制的作用。
至于为什么JDK8中使用synchronized而不是ReentrantLock,我猜是因为JDK8中对synchronized有了足够的优化吧。
十一、结合Util工具包
数组操控工具:Arrays工具累,Collections工具类
Collections工具类比较的内容必须继承Comparable接口
Collections比较常用的方法:原文:https://blog.csdn.net/u014067137/article/details/79871773
1、为List集合进行排序:Collections.sort()
2、返回集合(List和Set)中的最大最小值:Collections.max和 Collections.min
3、对List结合进行二分查找:Collections.binarySearch,在调用此方法前,需要先进行升序排列Collections.sort()。查询到返回位置否则返回-(index)-1.
4、反转集合内元素的顺序。reverse(反转List的顺序),reverseOrder(强行反转比较器的顺序)返回的是一个比较器。
5、将集合类变成线程安全的(synchronizedCollection(Collection
Comparable接口-可比较的:默认比较规则 实现该接口表示:这个类的实例可以比较大小,可以进行自然排序,定义了默认的比较规则 Comparable接口的实现类必须实现compateTo()方法 compareTo()方法返回正数表示大,负数表示小,0表示相等
Comparator接口-比较工具接口:临时比较规则,用于定义临时比较规则,而不是默认比较规则。 Comparator的实现类必须实现compare()方法 Comparable和Comparator都是java集合框架的成员
Java io
https://www.shiyanlou.com/courses/109/labs/1121/document/
大部分程序都需要进行输入/输出处理,比如从键盘读取数据、从屏幕中输出数据、从文件中写数据等等。在 Java 中,把这些不同类型的输入、输出源抽象为流(Stream),而其中输入或输出的数据则称为数据流(Data Stream),用统一的接口表示,从而使程序设计简单明了。
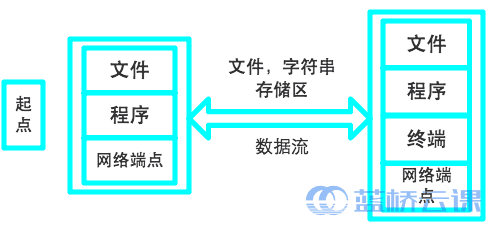
流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象。即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。
流一般分为输入流(Input Stream)和输出流(Output Stream)两类,但这种划分并不是绝对的。比如一个文件,当向其中写数据时,它就是一个输出流;当从其中读取数据时,它就是一个输入流。当然,键盘只是一个输入流,而屏幕则只是一个输出流。(其实我们可以通过一个非常简单的方法来判断,只要是向内存中写入就是输入流,从内存中写出就是输出流)
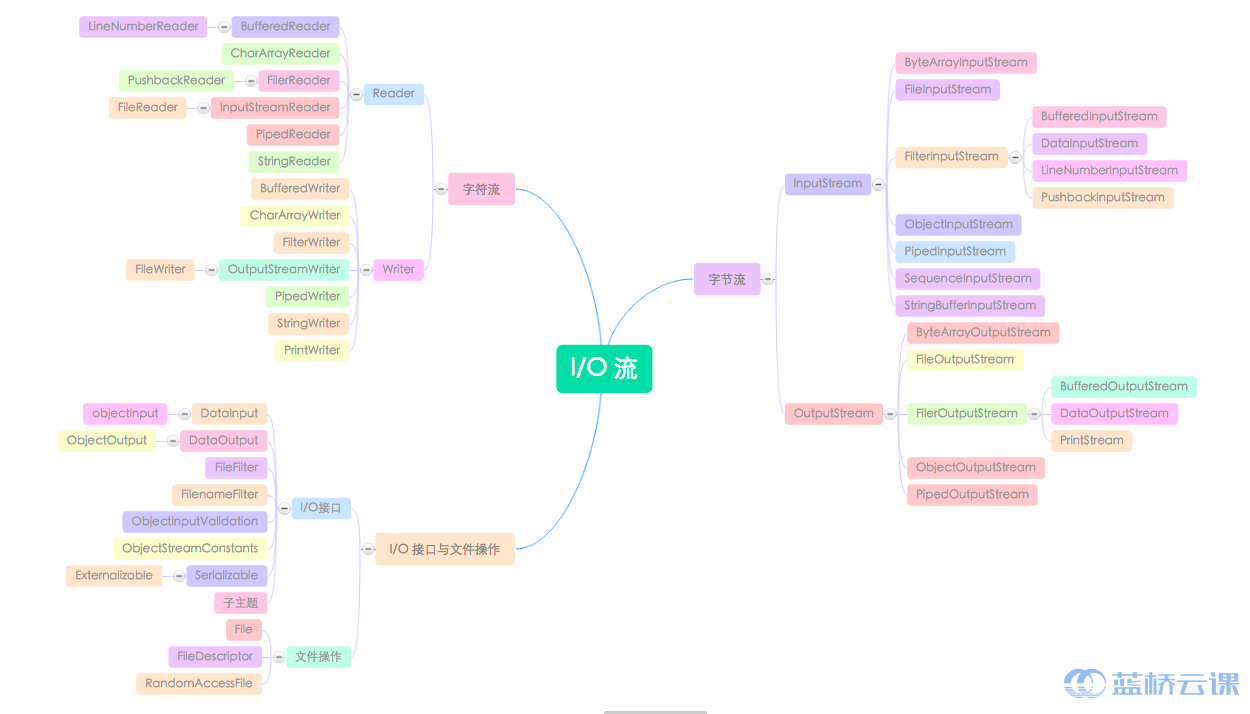
一、字节流
1、基类:InputStream 和 OutputStream
字节流主要操作 byte 类型数据,以 byte 数组为准,java 中每一种字节流的基本功能依赖于基本类 InputStream 和 Outputstream,他们是抽象类,不能直接使用。字节流能处理所有类型的数据(如图片、avi等)。
InputStream 是所有表示字节输入流类的基类,继承它的子类要重新定义其中所定义的抽象方法。InputStream 是从装置来源地读取数据的抽象表示,例如 System 中的标准输入流 in 对象就是一个 InputStream 类型的实例。
InputStream 类中,方法 read() 提供了三种从流中读数据的方法:
- int read():从输入流中读一个字节,形成一个 0~255 之间的整数返回(是一个抽象方法)
- int read(byte b[]):从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。
- int read(byte b[],int off,int len):从输入流中读取长度为 len 的数据,写入数组 b 中从索引 off 开始的位置,并返回读取得字节数。
对于这三个方法,若返回-1,表明流结束,否则,返回实际读取的字符数。
OutputStream 是所有表示字节输出流类的基类。子类要重新定义其中所定义的抽象方法,OutputStream 是用于将数据写入目的地的抽象表示。例如 System 中的标准输出流对象 out 其类型是 java.io.PrintStream,这个类是 OutputStream 的子类。
| 方法 | 说明 |
|---|---|
| write(int b)throws IOException | 将指定的字节写入此输出流(抽象方法),只写出一个byte到流,写的是b的低八位 |
| write(byte b[])throws IOException | 将字节数组中的数据输出到流中 |
| write(byte b[], int off, int len)throws IOException | 将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此输出流 |
| flush()throws IOException | 刷新此输出流并强制写出所有缓冲的输出字节 |
| close()throws IOException | 关闭流 |
例子:
xxxxxxxxxximport java.io.IOException;import java.io.InputStream;import java.io.OutputStream;public class test {/*** 把输入流中的所有内容赋值到输出流中* @param in* @param out* @throws IOException*/public void copy(InputStream in, OutputStream out) throws IOException {byte[] buf = new byte[4096];int len = in.read(buf);//read 是一个字节一个字节地读,字节流的结尾标志是-1while (len != -1){out.write(buf, 0, len);len = in.read(buf);}}public static void main(String[] args) throws IOException {// TODO Auto-generated method stubtest t = new test();System.out.println("输入字符:");t.copy(System.in, System.out);}}用例:输入字符:ABC输出:ABC
2、文件流
在 I/O 处理中,最常见的就是对文件的操作。java.io 包中所提供的文件操作类包括:
- 用于读写本地文件系统中的文件:FileInputStream 和 FileOutputStream
- 描述本地文件系统中的文件或目录:File、FileDescriptor 和 FilenameFilter
- 提供对本地文件系统中文件的随机访问支持:RandomAccessFile
今天我们来学习文件流的 FileInputStream 和 FileOutputStream 。
FileInputStream 类用于打开一个输入文件,若要打开的文件不存在,则会产生异常 FileNotFoundException,这是一个非运行时异常,必须捕获或声明抛弃;
FileOutputStream 类用来打开一个输出文件,若要打开的文件不存在,则会创建一个新的文件,否则原文件的内容会被新写入的内容所覆盖;
在进行文件的读/写操作时,会产生非运行时异常 IOException,必须捕获或声明抛弃(其他的输入/输出流处理时也同样需要进行输入/输出异常处理)。
文件流的构造方法:
xxxxxxxxxx//打开一个以 f 描述的文件作为输入FileInputStream(File f)//打开一个文件路径名为 name 的文件作为输入FileInputStream(String name)//创建一个以 f 描述的文件作为输出//如果文件存在,则其内容被清空FileOutputStream(File f)//创建一个文件路径名为 name 的文件作为输出//文件如果已经存在,则其内容被清空FileOutputStream(String name)//创建一个文件路径名为 name 的文件作为输出//文件如果已经存在,则在该输出上输出的内容被接到原有内容之后FileOutputStream(String name, boolean append)
3、缓冲流(速度快)
类 BufferedInputStream 和 BufferedOutputStream 实现了带缓冲的过滤流,它提供了缓冲机制,把任意的 I/O 流“捆绑”到缓冲流上,可以提高 I/O 流的读取效率。
在初始化时,除了要指定所连接的 I/O 流之外,还可以指定缓冲区的大小。缺省时是用 32 字节大小的缓冲区;最优的缓冲区大小常依赖于主机操作系统、可使用的内存空间以及机器的配置等;一般缓冲区的大小为内存页或磁盘块等的整数倍。
BufferedInputStream 的数据成员 buf 是一个位数组,默认为 2048 字节。当读取数据来源时例如文件,BufferedInputStream 会尽量将 buf 填满。当使用 read ()方法时,实际上是先读取 buf 中的数据,而不是直接对数据来源作读取。当 buf 中的数据不足时,BufferedInputStream 才会再实现给定的 InputStream 对象的 read() 方法,从指定的装置中提取数据。
BufferedOutputStream 的数据成员 buf 是一个位数组,默认为 512 字节。当使用 write() 方法写入数据时,实际上会先将数据写至 buf 中,当 buf 已满时才会实现给定的 OutputStream 对象的 write() 方法,将 buf 数据写至目的地,而不是每次都对目的地作写入的动作。
构造方法:
xxxxxxxxxx//[ ]里的内容代表选填BufferedInputStream(InputStream in [, int size])BufferedOutputStream(OutputStream out [, int size])
一般可以与其他字节流结合起来使用,例如:
xxxxxxxxxxFileInputStream in = new FileInputStream("file.txt");FileOutputStream out = new FileOutputStream("file2.txt");//设置输入缓冲区大小为256字节BufferedInputStream bin = new BufferedInputStream(in,256)BufferedOutputStream bout = new BufferedOutputStream(out,256)int len;byte bArray[] = new byte[256];len = bin.read(bArray); //len 中得到的是实际读取的长度,bArray 中得到的是数据
对于 BufferedOutputStream,只有缓冲区满时,才会将数据真正送到输出流,但可以使用 flush() 方法人为地将尚未填满的缓冲区中的数据送出。
4、 数据流
接口 DataInput 和 DataOutput,设计了一种较为高级的数据输入输出方式:除了可处理字节和字节数组外,还可以处理 int、float、boolean 等基本数据类型,这些数据在文件中的表示方式和它们在内存中的一样,无须转换,如 read(), readInt(), readByte()...; write(), writeChar(), writeBoolean()...此外,还可以用 readLine()方法读取一行信息。
- 分别实现了 DataInput 和 DataOutput 接口
- 在提供字节流的读写手段同时,以统一的形式向输入流中写入 boolean,int,long,double 等基本数据类型,并可以再次把基本数据类型的值读取回来。
- 提供了字符串读写的手段
数据流可以连接一个已经建立好的数据对象,例如网络连接、文件等。数据流可以通过如下方式建立:
xxxxxxxxxxFileInputStream fis = new FileInputStream("file1.txt");FileOutputStream fos = new FileOutputStream("file2.txt");DataInputStream dis = new DataInputStream(fis);DataOutputStream dos = new DataOutputStream(fos);
5、标准流、内存读写流、顺序输入流
标准流:
语言包 java.lang 中的 System 类管理标准输入/输出流和错误流。
System.in从 InputStream 中继承而来,用于从标准输入设备中获取输入数据(通常是键盘)System.out从 PrintStream 中继承而来,把输入送到缺省的显示设备(通常是显示器)System.err`也是从 PrintStream 中继承而来,把错误信息送到缺省的显示设备(通常是显示器)
每当 main 方法被执行时,就会自动生产上述三个对象。
内存读写流:
为了支持在内存上的 I/O,java.io 中提供了类:ByteArrayInputStream、ByteArrayOutputStream 和 StringBufferInputStream
- ByteArrayInputStream 可以从指定的字节数组中读取数据
- ByteArrayOutputStream 中提供了缓冲区可以存放数据(缓冲区大小可以在构造方法中设定,缺省为 32),可以用 write() 方法向其中写入数据,然后用 toByteArray() 方法将缓冲区中的有效字节写到字节数组中去。size() 方法可以知道写入的字节数;reset() 可以丢弃所有内容。
- StringBufferInputStream 与 ByteArrayInputStream 相类似,不同点在于它是从字符缓冲区 StringBuffer 中读取 16 位的 Unicode 数据,而不是 8 位的字节数据(已被 StringReader 取代)
顺序输入流
java.io 中提供了类 SequenceInputStream,使应用程序可以将几个输入流顺序连接起来。顺序输入流提供了将多个不同的输入流统一为一个输入流的功能,这使得程序可能变得更加简洁。
例如:
xxxxxxxxxxFileInputStream f1,f2;String s;f1 = new FileInputStream("file1.txt");f2 = new FileInputStream("file2.txt");SequenceInputStream fs = new SequenceInputStream(f1,f2);DataInputeStream ds = new DataInputStream(fs);while((s = ds.readLine()) != null) {System.out.println(s);}
二、字符流
1、基类:Reader 和 Writer
字符流以字符为单位,根据码表映射字符,一次可能读多个字节,只能处理字符类型的数据。
同类 InputStream 和 OutputStream 一样,Reader 和 Writer 也是抽象类,只提供了一系列用于字符流处理的接口。它们的方法与类 InputStream 和 OutputStream 类似,只不过其中的参数换成字符或字符数组。
Reader 是所有的输入字符流的父类,它是一个抽象类:
| 方法 | 返回值 |
|---|---|
| close() | void |
| mark (int readAheadLimit) | void |
| markSupported() | boolean |
| read() | int |
| read(char[] cbuf, int off,int len) | int |
| ready() | boolean |
| reset() | void |
| skip(long n) | long |
Writer 是所有的输出字符流的父类,它是一个抽象类。 Writer 的方法:
| 方法 | 返回值 |
|---|---|
| close() | void |
| flush() | void |
| write(char[] cbuf) | void |
| write(char[] cbuf, int off,int len) | void |
| write(int c) | void |
| write(String str) | void |
| write(String str, int off, int len) | void |
2、InputStreamReader 和 OutputStreamWriter
InputStreamReader 和 OutputStreamWriter 是 java.io 包中用于处理字符流的最基本的类,用来在字节流和字符流之间作为中介:从字节输入流读入字节,并按编码规范转换为字符;往字节输出流写字符时先将字符按编码规范转换为字节。使用这两者进行字符处理时,在构造方法中应指定一定的平台规范,以便把以字节方式表示的流转换为特定平台上的字符表示。
xxxxxxxxxxInputStreamReader(InputStream in); //缺省规范说明//指定规范 encInputStreamReader(InputStream in, String enc);OutputStreamWriter(OutputStream out); //缺省规范说明//指定规范 encOutputStreamWriter(OutputStream out, String enc);
如果读取的字符流不是来自本地时(比如网上某处与本地编码方式不同的机器),那么在构造字符输入流时就不能简单地使用缺省编码规范,而应该指定一种统一的编码规范“ISO 8859_1”,这是一种映射到 ASCCII 码的编码方式,能够在不同平台之间正确转换字符。
xxxxxxxxxxInputStreamReader ir = new InputStreamReader(is,"8859_1");
3、缓存流
除了 read() 和 write() 方法外,它还提供了整行字符处理方法:
- public String readLine():BufferedReader 的方法,从输入流中读取一行字符,行结束标志
\n、\r或者两者一起(这是根据系统而定的) - public void newLine():BufferedWriter 的方法,向输出流中写入一个行结束标志,它不是简单地换行符
\n或\r,而是系统定义的行隔离标志(line separator)。
例子:
xxxxxxxxxximport java.io.BufferedReader;import java.io.FileInputStream;import java.io.IOException;import java.io.InputStreamReader;public class FileToUnicode {public static void main(String args[]) {try {FileInputStream fis = new FileInputStream("file1.txt");InputStreamReader dis = new InputStreamReader(fis);BufferedReader reader = new BufferedReader(dis);String s;//每次读取一行,当改行为空时结束while((s = reader.readLine()) != null){System.out.println("read:" + s);}dis.close();}catch(IOException e) {System.out.println(e);}}}
4、其它字符流类
这里我们就列举一下有哪些类,具体的就不再讲解了。
对字符数组进行处理: CharArrayReader、CharArrayWrite
对文本文件进行处理:FileReader、FileWriter
对字符串进行处理:StringReader、StringWriter
过滤字符流:FilterReader、FileterWriter
管道字符流:PipedReader、PipedWriter
行处理字符流:LineNumberReader
打印字符流:PrintWriter
三、File文件操作
https://www.shiyanlou.com/courses/109/labs/1123/document/
java.io 定义的大多数类都是流式操作,但 File 类不是。它直接处理文件和文件系统。File 类没有指定信息怎样从文件读取或向文件存储;它描述了文件本身的属性。File 对象用来获取或处理与磁盘文件相关的信息,例如权限,时间,日期和目录路径。此外,File 还浏览子目录层次结构。Java 中的目录当成 File 对待,它具有附加的属性——一个可以被 list( )方法检测的文件名列表。
File 的构造方法:
xxxxxxxxxx//根据 parent 抽象路径名和 child 路径名字符串创建一个新 File 实例。File(File parent, String child)//通过将给定路径名字符串转换为抽象路径名来创建一个新 File 实例File(String pathname)// 根据 parent 路径名字符串和 child 路径名字符串创建一个新 File 实例File(String parent, String child)//通过将给定的 file: URI 转换为一个抽象路径名来创建一个新的 File 实例File(URI uri)
例如:
xxxxxxxxxx//一个目录路径参数File f1 = new File("/Users/mumutongxue/");//对象有两个参数——路径和文件名File f2 = new File("/Users/mumutongxue/","a.bat");//指向f1文件的路径及文件名File f3 = new File(f1,"a.bat");
四、RandomAccessFile类
- 该对象只能操作文件,所以构造函数接收两种类型的参数:a.字符串文件路径;b.File对象。
- 该对象既可以对文件进行读操作,也能进行写操作,在进行对象实例化时可指定操作模式(r,rw),支持随机访问文件,可以访问文件的任意位置;打开文件时文件指针在开头pointer=0;
- 写方法 raf.write(int) ---> 只写一个字节(后八位),同时指针指向下一个位置,或者也可以直接写入一个字节数组byte[],或者直接调用writeInt(i)
- 读方法int b=raf.read() --->读一个字节
RandomAccessFile 提供了支持随机文件操作的方法:
- readXXX()或者 writeXXX():如 ReadInt(),ReadLine(),WriteChar(),WriteDouble()等
- int skipBytes(int n):将指针向下移动若干字节
- length():返回文件长度
- long getFilePointer():返回指针当前位置
- void seek(long pos):将指针调用所需位置
在生成一个随机文件对象时,除了要指明文件对象和文件名之外,还需要指明访问文件的模式。
我们来看看 RandomAccessFile 的构造方法:
xxxxxxxxxxRandomAccessFile(File file,String mode)RandomAccessFile(String name,String mode)
mode 的取值:
r:只读,任何写操作都讲抛出 IOExceptionrw:读写,文件不存在时会创建该文件,文件存在是,原文件内容不变,通过写操作改变文件内容。rws:打开以便读取和写入,对于 "rw",还要求对文件的内容或元数据的每个更新都同步写入到底层存储设备。rwd:打开以便读取和写入,对于 "rw",还要求对文件内容的每个更新都同步写入到底层存储设备。
例子:
xxxxxxxxxximport java.io.IOException;import java.io.RandomAccessFile;public class FileDemo {public static void main(String[] args){int data_arr[] = {12, 32, 43, 45, 1, 5};try {RandomAccessFile randf=new RandomAccessFile("temp.dat","rw");for(int i = 0; i < data_arr.length; i++){randf.writeInt(data_arr[i]);}for(int i = data_arr.length-1 ; i >= 0; i--){//int 数据占4个字节randf.seek(i * 4L);System.out.println(randf.readInt());}randf.close();}catch(IOException e){System.out.println("File access error" + e);}}}输出结果:5 1 45 43 32 12
五、Serializable(序列化)
1、序列化是干什么的? 简单说就是为了保存在内存中的各种对象的状态(也就是实例变量,不是方法),并且可以把保存的对象状态再读出来。虽然你可以用你自己的各种各样的方法来保存object states,但是Java给你提供一种应该比你自己好的保存对象状态的机制,那就是序列化。
2、什么情况下需要序列化
a)当你想把的内存中的对象状态保存到一个文件中或者数据库中时候;
b)当你想用套接字在网络上传送对象的时候;
c)当你想通过RMI传输对象的时候;
Java并发性和多线程
进程
讲到线程,又不得不提进程了~
进程我们估计是很了解的了,在windows下打开任务管理器,可以发现我们在操作系统上运行的程序都是进程:

进程的定义:
进程是程序的一次执行,进程是一个程序及其数据在处理机上顺序执行时所发生的活动,进程是具有独立功能的程序在一个数据集合上运行的过程,它是系统进行资源分配和调度的一个独立单位
- 进程是系统进行资源分配和调度的独立单位。每一个进程都有它自己的内存空间和系统资源
并行和并发
并行:
- 并行性是指同一时刻内发生两个或多个事件。
- 并行是在不同实体上的多个事件
并发:
- 并发性是指同一时间间隔内发生两个或多个事件。
- 并发是在同一实体上的多个事件
由此可见:并行是针对进程的,并发是针对线程的。
- 并行:多个cpu实例或者多台机器同时执行一段处理逻辑,是真正的同时。
- 并发:通过cpu调度算法,让用户看上去同时执行,实际上从cpu操作层面不是真正的同时。并发往往在场景中有公用的资源,那么针对这个公用的资源往往产生瓶颈,我们会用TPS或者QPS来反应这个系统的处理能力。
线程和进程的区别?
进程是资源分配的最小单位,线程是程序执行的最小单位。
进程有自己的独立地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段、堆栈段和数据段,这种操作非常昂贵。而线程是共享进程中的数据的,使用相同的地址空间,因此CPU切换一个线程的花费远比进程要小很多,同时创建一个线程的开销也比进程要小很多。
线程之间的通信更方便,同一进程下的线程共享全局变量、静态变量等数据,而进程之间的通信需要以通信的方式(IPC)进行。不过如何处理好同步与互斥是编写多线程程序的难点。
但是多进程程序更健壮,多线程程序只要有一个线程死掉,整个进程也死掉了,而一个进程死掉并不会对另外一个进程造成影响,因为进程有自己独立的地址空间。
为什么会有线程?
每个进程都有自己的地址空间,即进程空间,在网络或多用户换机下,一个服务器通常需要接收大量不确定数量用户的并发请求,为每一个请求都创建一个进程显然行不通(系统开销大响应用户请求效率低),因此操作系统中线程概念被引进。
线程
线程状态
https://github.com/CyC2018/CS-Notes/blob/master/notes/Java%20并发.md#一线程状态转换
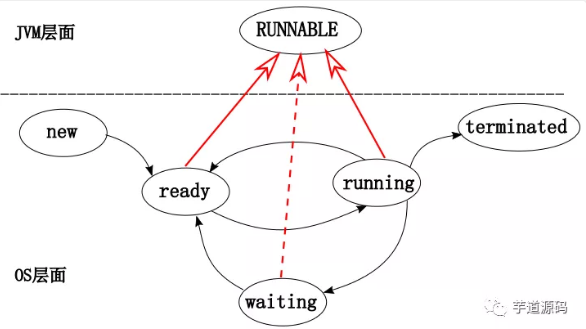
JVM线程状态:

下面看一下传统进(线)程状态划分:注:这里的进程指早期的单线程进程,这里所谓进程状态实质就是线程状态。【这个进程状态是底层的操作系统的状态,和jvm的线程状态不太一样,jvm是对这些状态做了自己的整理的】
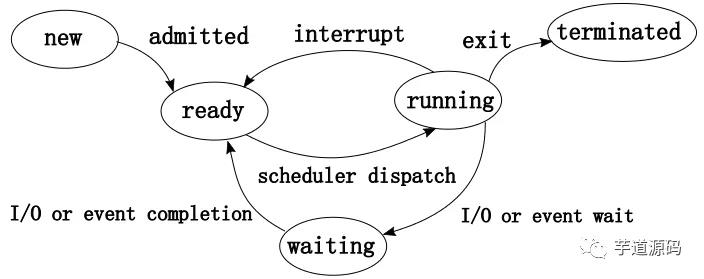
新建(New)
创建后尚未启动。
可运行(Runnable)
可能正在运行,也可能正在等待 CPU 时间片。
包含了操作系统线程状态中的 Running 和 Ready。
阻塞(Blocked)
等待获取一个排它锁,如果其线程释放了锁就会结束此状态。
共享锁就是允许多个线程同时获取一个锁,一个锁可以同时被多个线程拥有。
排它锁,也称作独占锁,一个锁在某一时刻只能被一个线程占有,其它线程必须等待锁被释放之后才可能获取到锁。
无限期等待(Waiting)
等待其它线程显式地唤醒,否则不会被分配 CPU 时间片。
| 进入方法 | 退出方法 |
|---|---|
| 没有设置 Timeout 参数的 Object.wait() 方法 | Object.notify() / Object.notifyAll() |
| 没有设置 Timeout 参数的 Thread.join() 方法 | 被调用的线程执行完毕 |
| LockSupport.park() 方法 | LockSupport.unpark(Thread) |
限期等待(Timed Waiting)
无需等待其它线程显式地唤醒,在一定时间之后会被系统自动唤醒。
调用 Thread.sleep() 方法使线程进入限期等待状态时,常常用“使一个线程睡眠”进行描述。
调用 Object.wait() 方法使线程进入限期等待或者无限期等待时,常常用“挂起一个线程”进行描述。
睡眠和挂起是用来描述行为,而阻塞和等待用来描述状态。
阻塞和等待的区别在于,阻塞是被动的,它是在等待获取一个排它锁。而等待是主动的,通过调用 Thread.sleep() 和 Object.wait() 等方法进入。
| 进入方法 | 退出方法 |
|---|---|
| Thread.sleep() 方法 | 时间结束 |
| 设置了 Timeout 参数的 Object.wait() 方法 | 时间结束 / Object.notify() / Object.notifyAll() |
| 设置了 Timeout 参数的 Thread.join() 方法 | 时间结束 / 被调用的线程执行完毕 |
| LockSupport.parkNanos() 方法 | LockSupport.unpark(Thread) |
| LockSupport.parkUntil() 方法 | LockSupport.unpark(Thread) |
死亡(Terminated)
可以是线程结束任务之后自己结束,或者产生了异常而结束。
为什么没有Running(正在运行状态)?
Java虚拟机层面所暴露给我们的状态,与操作系统底层的线程状态是两个不同层面的事。
答:现在的时分(time-sharing)多任务(multi-task)操作系统架构通常都是用所谓的“时间分片(time quantum or time slice)”方式进行抢占式(preemptive)轮转调度(round-robin式)。这个时间分片通常是很小的,一个线程一次最多只能在 cpu 上运行比如10-20ms 的时间(此时处于 running 状态),也即大概只有0.01秒这一量级,时间片用后就要被切换下来放入调度队列的末尾等待再次调度。,Java的线程状态是服务于监控的,如果线程切换得是如此之快,那么区分 ready 与 running 就没什么太大意义了。现今主流的 JVM 实现都把 Java 线程一一映射到操作系统底层的线程上,把调度委托给了操作系统,我们在虚拟机层面看到的状态实质是对底层状态的映射及包装。JVM 本身没有做什么实质的调度,把底层的 ready 及 running 状态映射上来也没多大意义,因此,统一成为runnable 状态是不错的选择。
其实:java虚拟机的RUNNABLE 状态对应了传统操作系统的 ready, running 以及部分的 waiting 状态。如下:
线程的使用
有三种使用线程的方法:
- 实现 Runnable 接口,重写 run(),new出来后作为参数传入Thred再调用start;
还可以直接写成这样:
xxxxxxxxxxThread thread = new Thread(new Runnable() {@Overridepublic void run() {counter++;//自己要写的内容}}).start();
- 实现 Callable 接口;与 Runnable 相比,Callable 可以有返回值,返回值通过 FutureTask 进行封装。
- 继承 Thread 类,重写run方法,直接new出来然后start。
实现 Runnable 和 Callable 接口的类只能当做一个可以在线程中运行的任务,不是真正意义上的线程,因此最后还需要通过 Thread 来调用。可以说任务是通过线程驱动从而执行的。
实现接口会更好一些,因为:
Java 不支持多重继承,因此继承了 Thread 类就无法继承其它类,但是可以实现多个接口;
类可能只要求可执行就行,继承整个 Thread 类开销过大。
将并发运行任务和运行机制解耦
run()和start()方法区别:
run():仅仅是封装被线程执行的代码,直接调用是普通方法start():首先启动了线程,然后再由jvm去调用该线程的run()方法。线程对象调用start()方法后,进入 就绪( Runnable)状态
jvm虚拟机的启动是单线程的还是多线程的?
- 是多线程的。不仅仅是启动main线程,还至少会启动垃圾回收线程的,不然谁帮你回收不用的内存~
与线程生命周期相关的方法
一、sleep
Thread.sleep(millisec) 方法会休眠当前正在执行的线程,millisec 单位为毫秒。等时间到了,进入的是就绪状态而并非是运行状态!会使当前线程进入TIMED_WAITING状态,但不释放对象锁,millis后线程自动苏醒进入就绪状态。作用:给其它线程执行机会的最佳方式。
obj.wait()
当前线程调用对象的wait()方法,当前线程释放对象锁,进入等待队列。依靠notify()/notifyAll()唤醒或者wait(long timeout) timeout时间到自动唤醒。
wait() 和 sleep() 的区别
- wait() 是 Object 的方法,而 sleep() 是 Thread 的静态方法;
- 1.使用sleep(long m)方法,在毫秒值结束之后,线程睡醒进入到Runnable可运行/Blocked阻塞状态 2.使用wait(long m)方法,wait方法如果在毫秒值结束之后,还没有被notify唤醒,就会自动醒来,线程睡醒进入到Runnable/Blocked状态
- wait() 会释放锁,sleep() 不会。
- wait可以指定时间也可以不指定,sleep必须指定时间。
- sleep必须捕获异常,wait可以不捕获
- wait、notify和notifyAll方法只能在(synchronized)同步方法或者同步代码块中使用,而sleep方法可以在任何地方使用。但是注意sleep是静态方法,也就是说它只对当前对象有效。通过对象名.sleep()想让该对象线程进入休眠是无效的,它只会让当前线程进入休眠。
二、yield方法
调用yield方法会先让别的线程执行,但是不确保真正让出,而且也只是建议具有相同优先级的其它线程可以运行。
意思是:我有空,可以的话,让你们先执行
Thread.yield(),一定是当前线程调用此方法,当前线程放弃获取的CPU时间片,但不释放锁资源,由运行状态变为就绪状态,让OS再次选择线程。作用:让相同优先级的线程轮流执行,但并不保证一定会轮流执行。实际中无法保证yield()达到让步目的,因为让步的线程还有可能被线程调度程序再次选中。Thread.yield()不会导致阻塞。该方法与sleep()类似,只是不能由用户指定暂停多长时间。
三、join方法
thread.join()/thread.join(long millis),当前线程里调用其它线程t的join方法,当前线程进入WAITING/TIMED_WAITING状态,当前线程不会释放已经持有的对象锁。线程t执行完毕或者millis时间到,当前线程一般情况下进入RUNNABLE状态,也有可能进入BLOCKED状态(因为join是基于wait实现的)。
四、interrupt方法
线程中断在之前的版本有stop方法,但是被设置过时了。现在已经没有强制线程终止的方法了!
- 要注意的是:interrupt不会真正停止一个线程,它仅仅是给这个线程发了一个信号告诉它,它应该要结束了(明白这一点非常重要!)
- 也就是说:Java设计者实际上是想线程自己来终止,通过上面的信号,就可以判断处理什么业务了。
- 具体到底中断还是继续运行,应该由被通知的线程自己处理,调用interrupt()并不是要真正终止掉当前线程,仅仅是设置了一个中断标志。这个中断标志可以给我们用来判断什么时候该干什么活!什么时候中断由我们自己来决定,这样就可以安全地终止线程了
如果一个线程的 run() 方法执行一个无限循环,并且没有执行 sleep() 等会抛出 InterruptedException 的操作,那么调用线程的 interrupt() 方法就无法使线程提前结束。
但是调用 interrupt() 方法会设置线程的中断标记,此时调用 interrupted() 方法会返回 true。因此可以在循环体中使用 interrupted() 方法来判断线程是否处于中断状态,从而提前结束线程。
xxxxxxxxxxpublic class InterruptExample {private static class MyThread2 extends Thread {@Overridepublic void run() {while (!interrupted()) {// ..}System.out.println("Thread end");}}}
InterruptedException
通过调用一个线程的 interrupt() 来中断该线程,如果该线程处于阻塞、限期等待或者无限期等待状态,那么就会抛出 InterruptedException,从而提前结束该线程。但是不能中断 I/O 阻塞和 synchronized 锁阻塞。
五、线程优先级设置
Thread提供了setPriority(int newPriority ) getPriority()方法来设置和返回指定线程的优先级,其中setPriority()方法的参数可以是一个整数,范围是0-10,之间,也可以使用Thread类的如下三个常量: 【注:在创建线程后的任何时候都可以设置(start前和start后都可以设置)】 MAX_PRIORITY 其值是10 MIN_PRIORITY 其值是1 NORM_PRIORITY 其值是5
- 记住当线程的优先级没有指定时,所有线程都携带普通优先级,也就是5。(main线程也具有普通优先级)
- 优先级可以用从1到10的范围指定。10表示最高优先级,1表示最低优先级,5是普通优先级。
- 记住优先级最高的线程在执行时被给予优先。但是不能保证线程在启动时就进入运行状态。
- 与在线程池中等待运行机会的线程相比,当前正在运行的线程可能总是拥有更高的优先级。
- 由调度程序决定哪一个线程被执行。
线程池
为每个请求都开一个新的线程虽然理论上是可以的,但是会有缺点:
- 线程生命周期的开销非常高。每个线程都有自己的生命周期,创建和销毁线程所花费的时间和资源可能比处理客户端的任务花费的时间和资源更多,并且还会有某些空闲线程也会占用资源。
- 程序的稳定性和健壮性会下降,每个请求开一个线程。如果受到了恶意攻击或者请求过多(内存不足),程序很容易就奔溃掉了。
所以说:我们的线程最好是交由线程池来管理,这样可以减少对线程生命周期的管理,一定程度上提高性能。
Executor 管理多个异步任务的执行,而无需程序员显式地管理线程的生命周期。这里的异步是指多个任务的执行互不干扰,不需要进行同步操作。
主要有三种 Executor:
- CachedThreadPool:一个任务创建一个线程,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。;
- FixedThreadPool:所有任务只能使用固定大小的线程,超出的线程会在队列中等待;
- SingleThreadExecutor:相当于大小为 1 的 FixedThreadPool,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
xxxxxxxxxxpublic static void main(String[] args) {ExecutorService executorService = Executors.newCachedThreadPool();for (int i = 0; i < 5; i++) {// 向线程池提交一个任务(其实就是通过线程池来启动一个线程)executorService.execute(new MyRunnable());}executorService.shutdown();}
synchronized
1. 同步一个代码块
xxxxxxxxxxpublic void func() {synchronized (this) {// ...}}
它只作用于同一个对象,如果调用两个对象上的同步代码块,就不会进行同步。
对于以下代码,使用 ExecutorService 执行了两个线程,由于调用的是同一个对象的同步代码块,因此这两个线程会进行同步,当一个线程进入同步语句块时,另一个线程就必须等待。
xxxxxxxxxxpublic class SynchronizedExample {public void func1() {synchronized (this) {for (int i = 0; i < 10; i++) {System.out.print(i + " ");}}}}public static void main(String[] args) {SynchronizedExample e1 = new SynchronizedExample();ExecutorService executorService = Executors.newCachedThreadPool();executorService.execute(() -> e1.func1());executorService.execute(() -> e1.func1());}0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9
对于以下代码,两个线程调用了不同对象的同步代码块,因此这两个线程就不需要同步。从输出结果可以看出,两个线程交叉执行。
xxxxxxxxxxpublic static void main(String[] args) {SynchronizedExample e1 = new SynchronizedExample();SynchronizedExample e2 = new SynchronizedExample();ExecutorService executorService = Executors.newCachedThreadPool();executorService.execute(() -> e1.func1());executorService.execute(() -> e2.func1());}0 0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9
2. 同步一个方法
xxxxxxxxxxpublic synchronized void func () {// ...}
它和同步代码块一样,作用于同一个对象。
3. 同步一个类
xxxxxxxxxxpublic void func() {synchronized (SynchronizedExample.class) {// ...}}
作用于整个类,也就是说两个线程调用同一个类的不同对象上的这种同步语句,也会进行同步。
xxxxxxxxxxpublic class SynchronizedExample {public void func2() {synchronized (SynchronizedExample.class) {for (int i = 0; i < 10; i++) {System.out.print(i + " ");}}}}public static void main(String[] args) {SynchronizedExample e1 = new SynchronizedExample();SynchronizedExample e2 = new SynchronizedExample();ExecutorService executorService = Executors.newCachedThreadPool();executorService.execute(() -> e1.func2());executorService.execute(() -> e2.func2());}0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9
4. 同步一个静态方法
xxxxxxxxxxpublic synchronized static void fun() {// ...}
作用于整个类。
Lock显式锁
简单概括一下:
- Lock方式来获取锁支持中断、超时不获取、是非阻塞的
- 提高了语义化,哪里加锁,哪里解锁都得写出来
- Lock显式锁可以给我们带来很好的灵活性,但同时我们必须手动释放锁
- 支持Condition条件对象
- 允许多个读线程同时访问共享资源
synchronized锁和Lock锁使用哪个
前面说了,Lock显式锁给我们的程序带来了很多的灵活性,很多特性都是Synchronized锁没有的。那Synchronized锁有没有存在的必要??
必须是有的!!Lock锁在刚出来的时候很多性能方面都比Synchronized锁要好,但是从JDK1.6开始Synchronized锁就做了各种的优化
- 优化操作:适应自旋锁,锁消除,锁粗化,轻量级锁,偏向锁。
- 详情可参考:https://blog.csdn.net/chenssy/article/details/54883355
所以,到现在Lock锁和Synchronized锁的性能其实差别不是很大!而Synchronized锁用起来又特别简单。Lock锁还得顾忌到它的特性,要手动释放锁才行(如果忘了释放,这就是一个隐患)
所以说,我们绝大部分时候还是会使用Synchronized锁,用到了Lock锁提及的特性,带来的灵活性才会考虑使用Lock显式锁~
https://github.com/CyC2018/CS-Notes/blob/master/notes/Java%20并发.md#synchronized
比较
1. 锁的实现
synchronized 是 JVM 实现的,而 ReentrantLock 是 JDK 实现的。
2. 性能
新版本 Java 对 synchronized 进行了很多优化,例如自旋锁等,synchronized 与 ReentrantLock 大致相同。
3. 等待可中断
当持有锁的线程长期不释放锁的时候,正在等待的线程可以选择放弃等待,改为处理其他事情。
ReentrantLock 可中断,而 synchronized 不行。
4. 公平锁
公平锁是指多个线程在等待同一个锁时,必须按照申请锁的时间顺序来依次获得锁。
synchronized 中的锁是非公平的,ReentrantLock 默认情况下也是非公平的,但是也可以是公平的。
5. 锁绑定多个条件
一个 ReentrantLock 可以同时绑定多个 Condition 对象。
使用选择
除非需要使用 ReentrantLock 的高级功能,否则优先使用 synchronized。这是因为 synchronized 是 JVM 实现的一种锁机制,JVM 原生地支持它,而 ReentrantLock 不是所有的 JDK 版本都支持。并且使用 synchronized 不用担心没有释放锁而导致死锁问题,因为 JVM 会确保锁的释放。
线程之间的协作wait() notify() notifyAll()
1、wait()、notify/notifyAll() 方法是Object的本地final方法,无法被重写。【wait可以接受毫秒数作为参数,表示等待多少秒后才进入就绪状态】
2、wait()使当前线程阻塞,前提是 必须先获得锁,一般配合synchronized 关键字使用,即,一般在synchronized 同步代码块里使用 wait()、notify/notifyAll() 方法。
3、 由于 wait()、notify/notifyAll() 在synchronized 代码块执行,说明当前线程一定是获取了锁的。
当线程执行wait()方法时候,会释放当前的锁,然后让出CPU,进入等待状态。
只有当 notify/notifyAll() 被执行时候,才会唤醒一个或多个正处于等待状态的线程,然后继续往下执行,直到执行完synchronized 代码块的代码或是中途遇到wait() ,再次释放锁。
也就是说,notify/notifyAll() 的执行只是唤醒沉睡的线程,而不会立即释放锁,锁的释放要看代码块的具体执行情况。所以在编程中,尽量在使用了notify/notifyAll() 后立即退出临界区,以唤醒其他线程
4、wait() 需要被try catch包围,中断也可以使wait等待的线程唤醒。
5、notify 和wait 的顺序不能错,如果A线程先执行notify方法,B线程在执行wait方法,那么B线程是无法被唤醒的。
6、notify 和 notifyAll的区别
notify方法只唤醒一个等待(对象的)线程并使该线程开始执行。所以如果有多个线程等待一个对象,这个方法只会唤醒其中一个线程,选择哪个线程取决于操作系统对多线程管理的实现。notifyAll 会唤醒所有等待(对象的)线程,尽管哪一个线程将会第一个处理取决于操作系统的实现。如果当前情况下有多个线程需要被唤醒,推荐使用notifyAll 方法。比如在生产者-消费者里面的使用,每次都需要唤醒所有的消费者或是生产者,以判断程序是否可以继续往下执行。
await() signal() signalAll()
java.util.concurrent 类库中提供了 Condition 类来实现线程之间的协调,可以在 Condition 上调用 await() 方法使线程等待,其它线程调用 signal() 或 signalAll() 方法唤醒等待的线程。
相比于 wait() 这种等待方式,await() 可以指定等待的条件,因此更加灵活。
使用 Lock 来获取一个 Condition 对象。
xxxxxxxxxxpublic class AwaitSignalExample {private Lock lock = new ReentrantLock();private Condition condition = lock.newCondition();public void before() {lock.lock();try {System.out.println("before");condition.signalAll();} finally {lock.unlock();}}public void after() {lock.lock();try {condition.await();System.out.println("after");} catch (InterruptedException e) {e.printStackTrace();} finally {lock.unlock();}}}public static void main(String[] args) {ExecutorService executorService = Executors.newCachedThreadPool();AwaitSignalExample example = new AwaitSignalExample();executorService.execute(() -> example.after());executorService.execute(() -> example.before());}beforeafter
J.U.C - AQS
java.util.concurrent下的AbstractQueuedSynchronizer抽象类简称为AQS
java.util.concurrent(J.U.C)大大提高了并发性能,AQS 被认为是 J.U.C 的核心。
概括一下AQS到底是什么:
juc包中很多可阻塞的类都是基于AQS构建的
- AQS可以说是一个给予实现同步锁、同步器的一个框架,很多实现类都在它的的基础上构建的
在AQS中实现了对等待队列的默认实现,子类只要重写部分的代码即可实现(大量用到了模板代码)
信号量
CountDownLatch
用来控制一个线程等待多个线程。
维护了一个计数器 cnt,每次调用 countDown() 方法会让计数器的值减 1,减到 0 的时候,那些因为调用 await() 方法而在等待的线程就会被唤醒。
CyclicBarrier
用来控制多个线程互相等待,只有当多个线程都到达时,这些线程才会继续执行。
和 CountdownLatch 相似,都是通过维护计数器来实现的。线程执行 await() 方法之后计数器会减 1,并进行等待,直到计数器为 0,所有调用 await() 方法而在等待的线程才能继续执行。
CyclicBarrier 和 CountdownLatch 的一个区别是,CyclicBarrier 的计数器通过调用 reset() 方法可以循环使用,所以它才叫做循环屏障。
CyclicBarrier 有两个构造函数,其中 parties 指示计数器的初始值,barrierAction 在所有线程都到达屏障的时候会执行一次。
Semaphore
Semaphore 类似于操作系统中的信号量,可以控制对互斥资源的访问线程数。
以下代码模拟了对某个服务的并发请求,每次只能有 3 个客户端同时访问,请求总数为 10。
xxxxxxxxxxpublic class SemaphoreExample {public static void main(String[] args) {final int clientCount = 3;final int totalRequestCount = 10;Semaphore semaphore = new Semaphore(clientCount);ExecutorService executorService = Executors.newCachedThreadPool();for (int i = 0; i < totalRequestCount; i++) {executorService.execute(()->{try {semaphore.acquire();System.out.print(semaphore.availablePermits() + " ");} catch (InterruptedException e) {e.printStackTrace();} finally {semaphore.release();}});}executorService.shutdown();}}2 1 2 2 2 2 2 1 2 2
ThreadLocal
ThreadLocal提供了线程的局部变量,每个线程都可以通过set()和get()来对这个局部变量进行操作,但不会和其他线程的局部变量进行冲突,实现了线程的数据隔离~。
ThreadLocal 从理论上讲并不是用来解决多线程并发问题的,因为根本不存在多线程竞争。
在一些场景 (尤其是使用线程池) 下,由于 ThreadLocal.ThreadLocalMap 的底层数据结构导致 ThreadLocal 有内存泄漏的情况,应该尽可能在每次使用 ThreadLocal 后手动调用 remove(),以避免出现 ThreadLocal 经典的内存泄漏甚至是造成自身业务混乱的风险。
原子性
原子性就是执行某一个操作是不可分割的,
xxxxxxxxxx- 比如上面所说的`count++`操作,它就不是一个原子性的操作,它是分成了三个步骤的来实现这个操作的~- **JDK中有atomic包提供给我们实现原子性操作**~
可见性
保证该变量对所有线程的可见性
- 在多线程的环境下:当这个变量修改时,所有的线程都会知道该变量被修改了,也就是所谓的“可见性”
volatile
使用了volatile修饰的变量保证了三点:
- 一致性:一旦你完成写入,任何访问这个字段的线程将会得到最新的值
- 在你写入前,会保证所有之前发生的事已经发生,并且任何更新过的数据值也是可见的,因为内存屏障会把之前的写入值都刷新到缓存。
- 有序性:volatile可以防止重排序(重排序指的就是:程序执行的时候,CPU、编译器可能会对执行顺序做一些调整,导致执行的顺序并不是从上往下的。从而出现了一些意想不到的效果)。而如果声明了volatile,那么CPU、编译器就会知道这个变量是共享的,不会被缓存在寄存器或者其他不可见的地方。
一般来说,volatile大多用于标志位上(判断操作),满足下面的条件才应该使用volatile修饰变量:
- 修改变量时不依赖变量的当前值(因为volatile是不保证原子性的,如果不需要原子性可以忽略)
- 该变量不会纳入到不变性条件中(该变量是可变的)
- 在访问变量的时候不需要加锁(加锁就没必要使用volatile这种轻量级同步机制了)
线程安全
多个线程不管以何种方式访问某个类,并且在主调代码中不需要进行同步,都能表现正确的行为。
线程安全有以下几种实现方式:
不可变
不可变(Immutable)的对象一定是线程安全的,不需要再采取任何的线程安全保障措施。只要一个不可变的对象被正确地构建出来,永远也不会看到它在多个线程之中处于不一致的状态。多线程环境下,应当尽量使对象成为不可变,来满足线程安全。
不可变的类型:
- final 关键字修饰的基本数据类型
- String
- 枚举类型
- Number 部分子类,如 Long 和 Double 等数值包装类型,BigInteger 和 BigDecimal 等大数据类型。但同为 Number 的原子类 AtomicInteger 和 AtomicLong 则是可变的。
非阻塞同步
互斥同步最主要的问题就是线程阻塞和唤醒所带来的性能问题,因此这种同步也称为阻塞同步。
互斥同步属于一种悲观的并发策略,总是认为只要不去做正确的同步措施,那就肯定会出现问题。无论共享数据是否真的会出现竞争,它都要进行加锁(这里讨论的是概念模型,实际上虚拟机会优化掉很大一部分不必要的加锁)、用户态核心态转换、维护锁计数器和检查是否有被阻塞的线程需要唤醒等操作。
无同步方案
要保证线程安全,并不是一定就要进行同步。如果一个方法本来就不涉及共享数据,那它自然就无须任何同步措施去保证正确性。